Appearance
业务背景:为啥需要短链?
公司电商产品推广、业务活动⻚、广告落地⻚缺少实时【数据反馈和渠道效果分析】
老项目业务推广【没人维护,无法做埋点】需要统计效果
APP和营销活动发送营销短信链接过⻓,【浪费短信发送费用】
SaaS平台盈利
用户按量付费,根据流量包选择付费购买对应的套餐
不同流量包权益不一样
每天可以创建的短链次数不一样
流量包使用时间限制、支持流量包叠加
注册用户每天有一定免费使用次数,但是不能查看数据
为什么需要学方法论
方法论: 通俗来说就是【做事套路,解决问题的方法(手段/途径/工具)】
为什么要学方法论,常⻅的有哪些是必备的
新业务规划(PEST)
指的是政治(Political)、经济(Economic)、社会 (Social)和技术(Technological)
政治环境主要是看我们的国家现在是否鼓励相关的业务
经济环境又可以分为宏观经济和微观经济,包括居⺠消费水平、产业结构
社会环境则是说跟社会的⻛俗习惯是否吻合
技术环境当然就是说的我们的技术实力(ASML光刻机)
运营推广(AARRR)
什么是AARRR用户增⻓模型
AARRR是Acquisition、Activation、Retention、Revenue、 Referral 五个单词的缩写,对应用户生命周期中的5个重要环节。
通俗来说就是一个产品从0~1到100的方法论
指引产品运营在不同的产品运营阶段,思考哪些关键节点,更好各个节点的指标数据
AARRR详细解释
获取:新用户首单免费/低价(瑞幸、拼多多)、厂商预装(手 机)、买量投放
激活:app推送、短信推送、产品价值激活
留存:签到、活动短信推送、平台价值提供
收益:平台广告、电商变现、付费会员、融资、软件服务
传播:好友助力、分享抽奖、兄弟砍我一刀
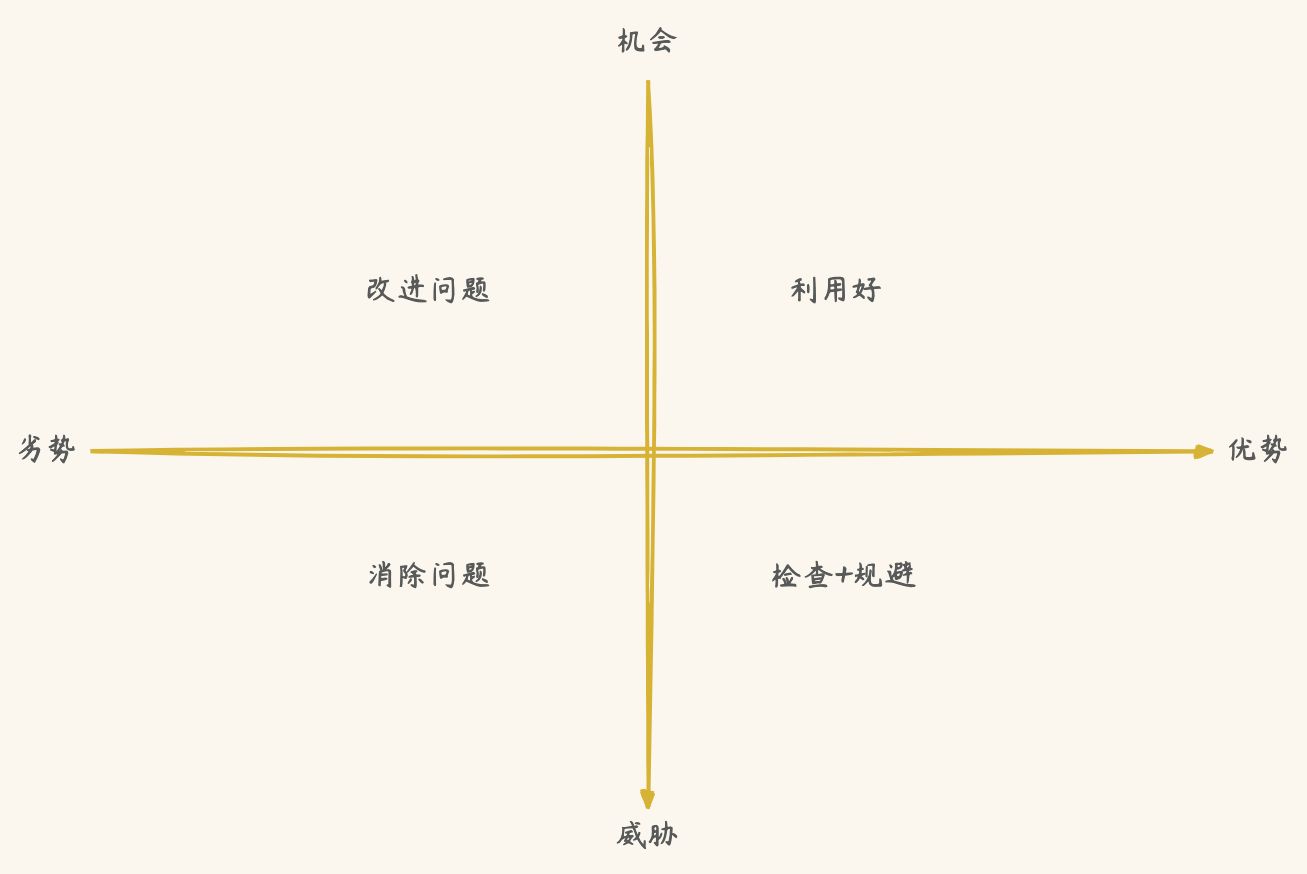
SWOT态势分析法
官方: 用来确定企业自身的竞争优势、劣势、外部市场的机会和威胁,从而将公司的战略与公司内部资源、外部环境有机地结合起来的一种科学的分析方法
4个单词的缩写 优势=strength、劣势=weakness、机会 =opportunity、威胁=threats
优势和弱势是内部环境的分析,机会和威胁是对于外部环境的分析
总结
- 外部的机会正好是你的优势,赶紧利用起来
- 外部的机会但是你的劣势,需要改进
- 自身具有优势但外部存在威胁,就需要时刻思考、保持警惕
- 是威胁又是你的劣势,就规避并消除
团队管理(SMART)
源于国外管理大师的《管理的实践》
是为了利于员工更加明确高效地工作,更是为了管理者将来对员工实施绩效考核提供了考核目标和考核标准,使考核更加科学化、规范化
是5个单词的缩写
Specific: 目标要具体
Measurable: 目标成果要可衡量(量化)
Attainable: 目标要可实现,避免过高/过低
Relevant: 与其他目标有一定的相关性
Time bound: 目标必须有明确的期限
意义: 在制定工作目标或者任务目标时,考虑一下目标与计划是不是SMART化的。只有具备SMART化的计划才是具有良好可实施性的,也才能指导保证计划得以实现
开发规范
开发人员
总负责人:1
| ### 岗位 | ### 运营+市场 | ### 设计 | ### 技术 | ### 产品 | | --- | --- | --- | --- | --- | | ### 负责人 | ### 1 | ### 1 | ### 1 | ### 1 | | ### 相关人员 | ### 用户运营1、内容运营1、渠道投放1、KA客户 | ### 1 | ### 后端4、前端2、测试1、运维1 | ### 产品需求1、数据分析1 |
项目业务的1号位,负责总把控各个事项,也是背负最大KPI压力的人,做的好也是最受益的人
岗位负责人:1号位正常都是带多个项目的,很少可能只带一个项目,基本只和岗位负责人进行对接岗位负责人负责团的组建和管理
一定要避免单点故障
一个微服务起码两个人熟悉:一个是主程一个是技术leader,推荐是团队里面两个开发人员
N方库说明
一方库: 本工程内部子项目模块依赖的库(jar包)。
二方库: 公司内部发布到中央仓库,可供公司内部其它应用依赖的库 (jar包)。
三方库: 公司之外的开源库(jar包)。
POJO实体类
POJO(Plain Ordinary Java Object): 在手册中,POJO 专指只有 setter / getter / toString 的简单类,包括DO/DTO/BO/VO 等,禁止命名成xxxPOJO
各个层级约束规范
Service/DAO层方法命名规约
获取单个对象的方法用get做前缀。
获取多个对象的方法用list做前缀,复数形式结尾,如: listObjects。
获取统计值的方法用count做前缀。
插入的方法用save/insert做前缀。
删除的方法用remove/delete做前缀。
修改的方法用update做前缀。
领域模型命名规约
数据对象: xxxDO,xxx即为数据表名。
一般数据传输对象: xxxDTO,xxx为业务领域相关的名称,项目里面也用VO。
展示对象: xxxVO,也就是响应给前端的实体包装类。
接收前端json对象请求的命名为XXXRequest
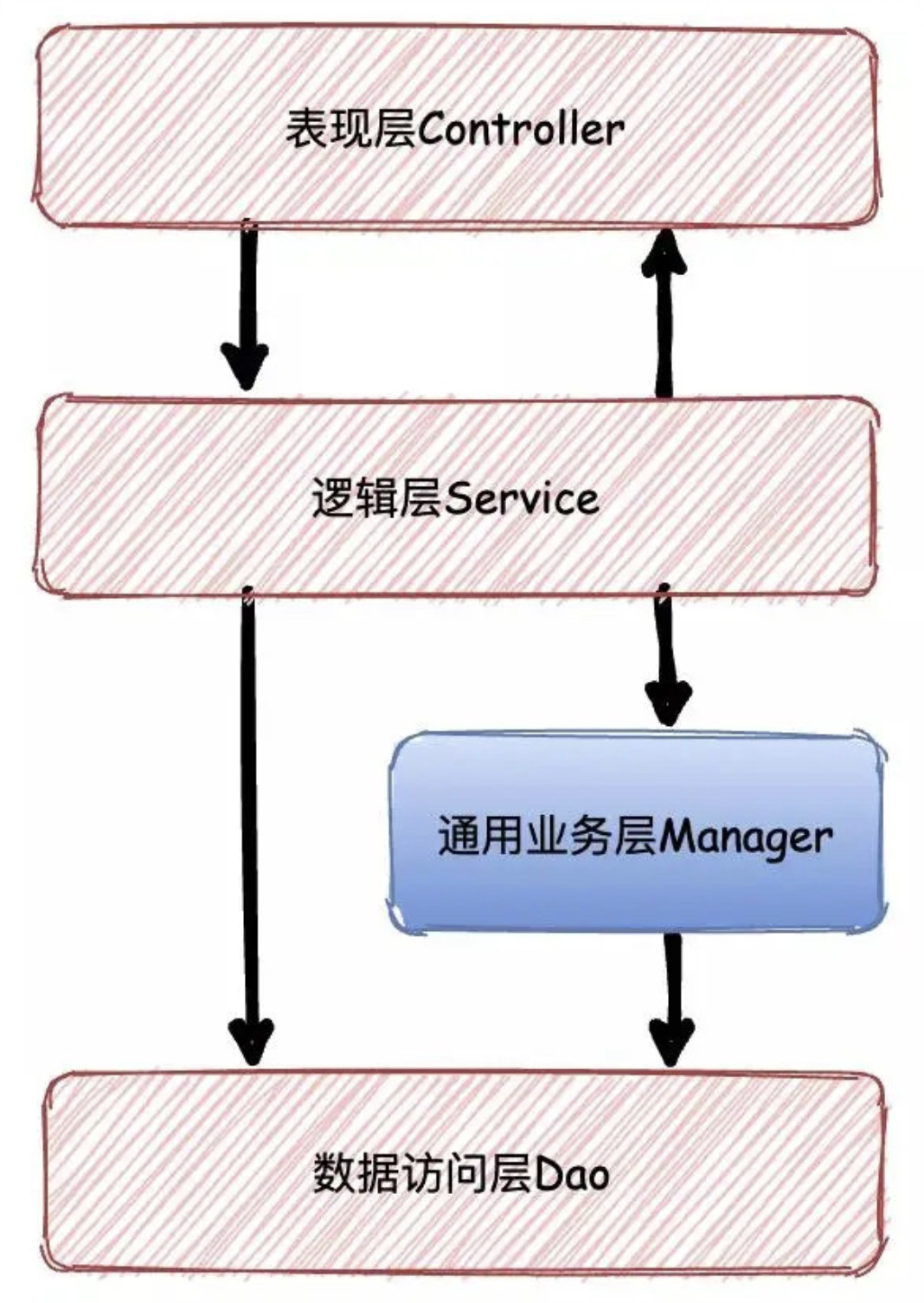
Manager分层说明
通用业务处理层,它有如下特征
对第三方平台封装的层,预处理返回结果及转化异常信息
对Service层通用能力的下沉,如缓存方案、中间件通用处理
与DAO层交互,对多个DAO的组合复用。
统一接口响应协议-响应工具类封装
1. 新建enums包,在新建的包中新建BizCodeEnum枚举。
统一业务状态码 BizCodeEnum,这是一个枚举类。
2. 新建util包,在新建的包中新建JsonData类。
java
@Data
@AllArgsConstructor
@NoArgsConstructor
public class JsonData {
/**
* 状态码 0 表示成功
*/
private Integer code;
/**
* 数据
*/
private Object data;
/**
* 描述
*/
private String msg;
/**
* 获取远程调用数据
* 注意事项:
* 支持多单词下划线专驼峰(序列化和反序列化)
*
* @param typeReference
* @param <T>
* @return
*/
public <T> T getData(TypeReference<T> typeReference){
return JSON.parseObject(JSON.toJSONString(data),typeReference);
}
/**
* 成功,不传入数据
* @return
*/
public static JsonData buildSuccess() {
return new JsonData(0, null, null);
}
/**
* 成功,传入数据
* @param data
* @return
*/
public static JsonData buildSuccess(Object data) {
return new JsonData(0, data, null);
}
/**
* 失败,传入描述信息
* @param msg
* @return
*/
public static JsonData buildError(String msg) {
return new JsonData(-1, null, msg);
}
/**
* 自定义状态码和错误信息
* @param code
* @param msg
* @return
*/
public static JsonData buildCodeAndMsg(int code, String msg) {
return new JsonData(code, null, msg);
}
/**
* 传入枚举,返回信息
* @param codeEnum
* @return
*/
public static JsonData buildResult(BizCodeEnum codeEnum){
return JsonData.buildCodeAndMsg(codeEnum.getCode(),codeEnum.getMessage());
}
}自定义全局异常+处理器开发
1. 新建exception包,在新建的包中新建BizException类。
java
@Data
public class BizException extends RuntimeException {
private int code;
private String msg;
public BizException(Integer code, String message) {
super(message);
this.code = code;
this.msg = message;
}
public BizException(BizCodeEnum bizCodeEnum){
super(bizCodeEnum.getMessage());
this.code = bizCodeEnum.getCode();
this.msg = bizCodeEnum.getMessage();
}
}2. 继续,在新建的包中新建CustomExceptionHandler类,它是一个全局异常处理器。
java
@ControllerAdvice
//@RestControllerAdvice
@Slf4j
public class CustomExceptionHandler {
@ExceptionHandler(value = Exception.class)
@ResponseBody
public JsonData handler(Exception e){
if(e instanceof BizException){
BizException bizException = (BizException) e;
log.error("[业务异常]{}",e);
return JsonData.buildCodeAndMsg(bizException.getCode(),bizException.getMsg());
}else {
log.error("[系统异常]{}",e);
return JsonData.buildError("系统异常");
}
}
}common通用工具和时间格式化工具类
时间格式化工具类封装
java
public class TimeUtil {
/**
* 默认日期格式
*/
private static final String DEFAULT_PATTERN = "yyyy-MM-dd HH:mm:ss";
/**
* 默认日期格式
*/
private static final DateTimeFormatter DEFAULT_DATE_TIME_FORMATTER = DateTimeFormatter.ofPattern(DEFAULT_PATTERN);
private static final ZoneId DEFAULT_ZONE_ID = ZoneId.systemDefault();
/**
* LocalDateTime 转 字符串,指定日期格式
* @param localDateTime
* @param pattern
* @return
*/
public static String format(LocalDateTime localDateTime, String pattern){
DateTimeFormatter formatter = DateTimeFormatter.ofPattern(pattern);
String timeStr = formatter.format(localDateTime.atZone(DEFAULT_ZONE_ID));
return timeStr;
}
/**
* Date 转 字符串, 指定日期格式
* @param time
* @param pattern
* @return
*/
public static String format(Date time, String pattern){
DateTimeFormatter formatter = DateTimeFormatter.ofPattern(pattern);
String timeStr = formatter.format(time.toInstant().atZone(DEFAULT_ZONE_ID));
return timeStr;
}
/**
* Date 转 字符串,默认日期格式
* @param time
* @return
*/
public static String format(Date time){
String timeStr = DEFAULT_DATE_TIME_FORMATTER.format(time.toInstant().atZone(DEFAULT_ZONE_ID));
return timeStr;
}
/**
* timestamp 转 字符串,默认日期格式
*
* @param timestamp
* @return
*/
public static String format(long timestamp) {
String timeStr = DEFAULT_DATE_TIME_FORMATTER.format(new Date(timestamp).toInstant().atZone(DEFAULT_ZONE_ID));
return timeStr;
}
/**
* 字符串 转 Date
*
* @param time
* @return
*/
public static Date strToDate(String time) {
LocalDateTime localDateTime = LocalDateTime.parse(time, DEFAULT_DATE_TIME_FORMATTER);
return Date.from(localDateTime.atZone(DEFAULT_ZONE_ID).toInstant());
}
/**
* 获取当天剩余的秒数,用于流量包过期配置
* @param currentDate
* @return
*/
public static Integer getRemainSecondsOneDay(Date currentDate) {
LocalDateTime midnight = LocalDateTime.ofInstant(currentDate.toInstant(),
ZoneId.systemDefault()).plusDays(1).withHour(0).withMinute(0)
.withSecond(0).withNano(0);
LocalDateTime currentDateTime = LocalDateTime.ofInstant(currentDate.toInstant(),
ZoneId.systemDefault());
long seconds = ChronoUnit.SECONDS.between(currentDateTime, midnight);
return (int) seconds;
}
}Json序列化工具类封装
生产环境不能用e.printStackTrace()输出堆栈,有性能影响。

java
@Slf4j
public class JsonUtil {
private static final ObjectMapper mapper = new ObjectMapper();
static {
//设置可用单引号
mapper.configure(JsonParser.Feature.ALLOW_SINGLE_QUOTES, true);
//序列化的时候序列对象的所有属性
mapper.setSerializationInclusion(JsonInclude.Include.ALWAYS);
//反序列化的时候如果多了其他属性,不抛出异常
mapper.configure(DeserializationFeature.FAIL_ON_UNKNOWN_PROPERTIES, false);
//如果是空对象的时候,不抛异常
mapper.configure(SerializationFeature.FAIL_ON_EMPTY_BEANS, false);
//取消时间的转化格式,默认是时间戳,可以取消,同时需要设置要表现的时间格式
mapper.configure(SerializationFeature.WRITE_DATES_AS_TIMESTAMPS, false);
mapper.setDateFormat(new SimpleDateFormat("yyyy-MM-dd HH:mm:ss"));
}
/**
* 对象转为Json字符串
* @param obj
* @return
*/
public static String obj2Json(Object obj) {
String jsonStr = null;
try {
jsonStr = mapper.writeValueAsString(obj);
} catch (JsonProcessingException e) {
//e.printStackTrace();
log.error("json格式化异常:{}",e);
}
return jsonStr;
}
/**
* json字符串转为对象
* @param jsonStr
* @param beanType
* @return
*/
public static <T> T json2Obj(String jsonStr, Class<T> beanType) {
T obj = null;
try {
obj = mapper.readValue(jsonStr, beanType);
} catch (Exception e){
//e.printStackTrace();
log.error("json格式化异常:{}",e);
}
return obj;
}
/**
* json数据转换成pojo对象list
* @param jsonData
* @param beanType
* @return
*/
public static <T> List<T> json2List(String jsonData, Class<T> beanType) {
JavaType javaType = mapper.getTypeFactory().constructParametricType(List.class, beanType);
try {
List<T> list = mapper.readValue(jsonData, javaType);
return list;
} catch (Exception e) {
//e.printStackTrace();
log.error("json格式化异常:{}",e);
}
return null;
}
/**
* 对象转为byte数组
* @param obj
* @return
*/
public static byte[] obj2Bytes(Object obj) {
byte[] byteArr = null;
try {
byteArr = mapper.writeValueAsBytes(obj);
} catch (JsonProcessingException e) {
//e.printStackTrace();
log.error("json格式化异常:{}",e);
}
return byteArr;
}
/**
* byte数组转为对象
* @param byteArr
* @param beanType
* @return
*/
public static <T> T bytes2Obj(byte[] byteArr, Class<T> beanType) {
T obj = null;
try {
obj = mapper.readValue(byteArr, beanType);
} catch (Exception e) {
//e.printStackTrace();
log.error("json格式化异常:{}",e);
}
return obj;
}
}common工具大集合
java
@Slf4j
public class CommonUtil {
/**
* 获取ip
*
* @param request
* @return
*/
public static String getIpAddr(HttpServletRequest request) {
String ipAddress = null;
try {
ipAddress = request.getHeader("x-forwarded-for");
if (ipAddress == null || ipAddress.length() == 0 || "unknown".equalsIgnoreCase(ipAddress)) {
ipAddress = request.getHeader("Proxy-Client-IP");
}
if (ipAddress == null || ipAddress.length() == 0 || "unknown".equalsIgnoreCase(ipAddress)) {
ipAddress = request.getHeader("WL-Proxy-Client-IP");
}
if (ipAddress == null || ipAddress.length() == 0 || "unknown".equalsIgnoreCase(ipAddress)) {
ipAddress = request.getRemoteAddr();
if (ipAddress.equals("127.0.0.1")) {
// 根据网卡取本机配置的IP
InetAddress inet = null;
try {
inet = InetAddress.getLocalHost();
} catch (UnknownHostException e) {
// e.printStackTrace();
log.warn("获取ip异常", e);
}
ipAddress = inet.getHostAddress();
}
}
// 对于通过多个代理的情况,第一个IP为客户端真实IP,多个IP按照','分割
if (ipAddress != null && ipAddress.length() > 15) {
// "***.***.***.***".length()
// = 15
if (ipAddress.indexOf(",") > 0) {
ipAddress = ipAddress.substring(0, ipAddress.indexOf(","));
}
}
} catch (Exception e) {
ipAddress = "";
}
return ipAddress;
}
/**
* 获取全部请求头
*
* @param request
* @return
*/
public static Map<String, String> getAllRequestHeader(HttpServletRequest request) {
Enumeration<String> headerNames = request.getHeaderNames();
Map<String, String> map = new HashMap<>();
while (headerNames.hasMoreElements()) {
String key = (String) headerNames.nextElement();
//根据名称获取请求头的值
String value = request.getHeader(key);
map.put(key, value);
}
return map;
}
/**
* MD5加密
*
* @param data
* @return
*/
public static String MD5(String data) {
try {
MessageDigest md = MessageDigest.getInstance("MD5");
byte[] array = md.digest(data.getBytes("UTF-8"));
StringBuilder sb = new StringBuilder();
for (byte item : array) {
sb.append(Integer.toHexString((item & 0xFF) | 0x100).substring(1, 3));
}
return sb.toString().toUpperCase();
} catch (Exception exception) {
}
return null;
}
/**
* 获取验证码随机数
*
* @param length
* @return
*/
public static String getRandomCode(int length) {
String sources = "0123456789";
Random random = new Random();
StringBuilder sb = new StringBuilder();
for (int j = 0; j < length; j++) {
sb.append(sources.charAt(random.nextInt(9)));
}
return sb.toString();
}
/**
* 获取当前时间戳
*
* @return
*/
public static long getCurrentTimestamp() {
return System.currentTimeMillis();
}
/**
* 生成uuid
*
* @return
*/
public static String generateUUID() {
return UUID.randomUUID().toString().replaceAll("-", "").substring(0, 32);
}
/**
* 获取随机长度的串
*
* @param length
* @return
*/
private static final String ALL_CHAR_NUM = "0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz";
public static String getStringNumRandom(int length) {
//生成随机数字和字母,
Random random = new Random();
StringBuilder saltString = new StringBuilder(length);
for (int i = 1; i <= length; ++i) {
saltString.append(ALL_CHAR_NUM.charAt(random.nextInt(ALL_CHAR_NUM.length())));
}
return saltString.toString();
}
/**
* 响应json数据给前端
*
* @param response
* @param obj
*/
public static void sendJsonMessage(HttpServletResponse response, Object obj) {
response.setContentType("application/json; charset=utf-8");
try (PrintWriter writer = response.getWriter()) {
writer.print(JsonUtil.obj2Json(obj));
response.flushBuffer();
} catch (IOException e) {
log.warn("响应json数据给前端异常:{}", e);
}
}
}Q: 海量数据下每天免费次数怎么更新?
记录中...
Q: 海量数据付费流量套餐包每天次数限制怎么更新?
记录中...
Q: 高性能扣减流量包设计怎么做?
记录中...
Q: 流量包数据更新处理-高并发下分布式事务怎么解决
记录中...
账号微服务注册模块+短信验证码
功能需求
使用手机号注册,已经注册的手机号不能︎重复注册,密码不能使用简单的MD5加密
用户上传头像需要用文件存储
安全需求
高并发下账号唯一性,注册邮箱或者手机验证码不能被恶意调用
验证码+唯一索引
头像文件存储访问方便扩容和管理
阿里云OSS
高并发处理
异步+池化思想
短链平台选择
使用短信验证码注册
头像存储使用阿里云OSS
Jmeter压测
开源免费,功能强大,在互联网公司普遍使用
常规压测流程
内网环境
非GUI下压测
停止其他无关资源进程
压测机和被压测机器隔离
Q: 高并发下异步请求解决方案-@Async注解
同步发送请求在高并发下有性能问题,用测试工具压测结果:
错误: Connection timed out
400到500qps
解决方式是异步发送+池化思想
A: @Async组件
使用场景
适用于处理log、发送邮件、短信......等
涉及到网络IO调用等操作
使用方式
启动类里面使用@EnableAsync注解开启功能,自动扫描
定义异步任务类并使用@Component标记组件被容器扫描,异步方法加上@Async
@Async失效情况
注解@Async的方法不是public方法
注解@Async的返回值只能为void或者Future
注解@Async方法使用static修饰也会失效
spring无法扫描到异步类,没加注解@Async 或 @EnableAsync注解
调用方与被调方不能在同一个类
Spring 在扫描bean的时候会扫描方法上是否包含@Async注解,动态地生成一个子类(即proxy代理类),当这个有注解的方法被调用的时候,实际上是由代理类来调用的,代理类在调用时增加异步作用
如果这个有注解的方法是被同一个类中的其他方法调用的,那么该方法的调用并没有通过代理类,而是直接通过原来的那个bean,所以就失效了
所以调用方与被调方不能在同一个类,主要是使用了动态代理,同一个类的时候直接调用,不是通过生成的动态代理类调用
一般将要异步执行的方法单独抽取成一个类
类中需要使用@Autowired或@Resource等注解自动注入,不能自己手动new对象
在Async方法上标注@Transactional是没用的,但在Async方法调用的方法上标注@Transactional是有效的
线程池默认机制问题
压测后很快跑完全部内容,是因为都在线程池内部的阻塞队列里面
极容易出现OOM,或者消息丢失
默认线程策略说明
代码位置
TaskExecutionProperties
TaskExecutionAutoConfiguration
若未指定线程池,使用 @Async 注解时,将默认使用 Spring 创建的 ThreadPoolTaskExecutor。
核心线程数:8
最大线程数:Integer.MAX_VALUE(约 21 亿多)
队列类型:LinkedBlockingQueue
队列容量:Integer.MAX_VALUE
空闲线程保留时间:60 秒
线程池拒绝策略:AbortPolicy
线程池工作机制
当新任务到达并且当前运行的线程数少于核心线程数时,线程池会创建新线程来处理任务,即使有空闲线程。
当运行的线程数达到核心线程数但小于最大线程数时,新来的任务会被加入到队列中(如果队列已满,则会创建新线程,直到达到最大线程数)。
如果运行的线程数已经等于最大线程数,新来的任务将会根据配置的拒绝策略被处理,例如抛出异常、运行拒绝任务的处理程序等。
自定义线程池策略
Spring线程池的默认行为可能不会适当地处理运行时异常。如果没有正确配置错误处理逻辑,这可能导致问题被忽略或不正确地处理。
存在OOM风险,所以需要根据情况重新配置线程池策略。
java
@Configuration
@EnableAsync
public class ThreadPoolTaskConfig {
@Bean("threadPoolTaskExecutor")
public ThreadPoolTaskExecutor threadPoolTaskExecutor(){
ThreadPoolTaskExecutor executor = new ThreadPoolTaskExecutor();
//线程池创建的核心线程数,线程池维护线程的最少数量,即使没有任务需要执行,也会一直存活
//如果设置allowCoreThreadTimeout=true(默认false)时,核心线程会超时关闭
executor.setCorePoolSize(16);
//executor.setAllowCoreThreadTimeOut();
//阻塞队列 当核心线程数达到最大时,新任务会放在队列中排队等待执行
executor.setQueueCapacity(124);
//最大线程池数量,当线程数>=corePoolSize,且任务队列已满时。线程池会创建新线程来处理任务
//任务队列已满时, 且当线程数=maxPoolSize,,线程池会拒绝处理任务而抛出异常
executor.setMaxPoolSize(64);
//当线程空闲时间达到keepAliveTime时,线程会退出,直到线程数量=corePoolSize
//允许线程空闲时间30秒,当maxPoolSize的线程在空闲时间到达的时候销毁
//如果allowCoreThreadTimeout=true,则会直到线程数量=0
executor.setKeepAliveSeconds(30);
//spring 提供的 ThreadPoolTaskExecutor 线程池,是有 setThreadNamePrefix() 方法的。
//jdk 提供的ThreadPoolExecutor 线程池是没有 setThreadNamePrefix() 方法的
executor.setThreadNamePrefix("自定义线程池-");
// rejection-policy:当pool已经达到max size的时候,如何处理新任务
// CallerRunsPolicy():交由调用方线程运行,比如 main 线程;如果添加到线程池失败,那么主线程会自己去执行该任务,不会等待线程池中的线程去执行
// AbortPolicy():该策略是线程池的默认策略,如果线程池队列满了丢掉这个任务并且抛出RejectedExecutionException异常。
// DiscardPolicy():如果线程池队列满了,会直接丢掉这个任务并且不会有任何异常
// DiscardOldestPolicy():丢弃队列中最老的任务,队列满了,会将最早进入队列的任务删掉腾出空间,再尝试加入队列
executor.setRejectedExecutionHandler(new ThreadPoolExecutor.AbortPolicy());
executor.initialize();
return executor;
}
}指定自定义线程池
java
@Async("threadPoolTaskExecutor")总结
先是CorePoolSize是否满足,然后是Queue阻塞队列是否满,最后才是MaxPoolSize是否满足
Q: ThreadPoolTaskExecutor线程池有哪几个重要参数,什么时候会创建线程?
查看核心线程池是否已满,不满就创建一条线程执行任务,否则执行第二步。
查看阻塞队列是否已满,不满就将任务存储在阻塞队列中,否则执行第三步。
查看线程池是否已满,即是否达到最大线程池数,不满就创建一条线程执行任务,否则就按照策略处理无法执行的任务。
Q: 高并发下核心线程怎么设置?
分IO密集还是CPU密集,一般情况按以下设置性能更好
CPU密集设置为跟核心数一样大小
IO密集型设置为2倍CPU核心数
没有固定的参数,根据实际情况压测进行调整
消费方⻆度,提高消费能力
客户端每次请求都要和服务端建立新的连接,即三次握手将会非常耗时
通过http连接池可以减少连接建立与释放的时间,提升http请求的性能
Spring的restTemplate是对httpclient进行了封装, 而httpclient是支持池化机制
拓展
对httpclient进行封装的有: Apache的Fluent、es的 restHighLevelClient、spring的restTemplate等
配置RestTemplate连接池
java
@Configuration
public class RestTemplateConfig {
@Bean
public RestTemplate restTemplate(ClientHttpRequestFactory requestFactory){
return new RestTemplate(requestFactory);
}
@Bean
public ClientHttpRequestFactory httpRequestFactory(){
return new HttpComponentsClientHttpRequestFactory(httpClient());
}
@Bean
public HttpClient httpClient(){
Registry<ConnectionSocketFactory> registry = RegistryBuilder.<ConnectionSocketFactory>create()
.register("http", PlainConnectionSocketFactory.getSocketFactory())
.register("https", SSLConnectionSocketFactory.getSocketFactory())
.build();
PoolingHttpClientConnectionManager connectionManager = new PoolingHttpClientConnectionManager(registry);
//设置连接池最大是500个连接
connectionManager.setMaxTotal(500);
//MaxPerRoute是对maxTotal的细分,每个主机的并发最大是300,route是指域名
connectionManager.setDefaultMaxPerRoute(300);
/**
* 只请求resonance.fun, 最大并发300
*
* 请求resonance.fun, 最大并发300
* 请求open1024.com, 最大并发200
*/
RequestConfig requestConfig = RequestConfig.custom()
//返回数据的超时时间
.setSocketTimeout(20000)
//连接上服务器的超时时间
.setConnectTimeout(10000)
//从连接池中获取连接的超时时间
.setConnectionRequestTimeout(1000)
.build();
CloseableHttpClient closeableHttpClient = HttpClientBuilder.create().setDefaultRequestConfig(requestConfig)
.setConnectionManager(connectionManager)
.build();
return closeableHttpClient;
}
}10倍+提升: Jmeter5.x压测优化后RestTemplate前后性能对比
同步发送+resttemplate未池化
压测结果:几百qps
异步发送+resttemplate池化
压测结果:2000~3000qps,但这是同一台机器,实际分开测试更高
池化思想应用-Redis6.X配置连接池实战
连接池好处
使用连接池不用每次都走三次握手、每次都关闭Jedis
注意
相对于直连,使用相对麻烦,在资源管理上需要很多参数来保证,规划不合理也会出现问题
如果pool已经分配了maxActive个jedis实例,则此时pool的状态就成exhausted了
连接池配置common项目
xml
<!--redis客户端-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
<exclusions>
<exclusion>
<groupId>io.lettuce</groupId>
<artifactId>lettuce-core</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
</dependency>
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>配置Redis连接
yaml
redis:
client-type: jedis
host: 47.108.67.134
password: resonancefun
port: 8000
jedis:
pool:
# 连接池最大连接数(使用负值表示没有限制)
max-active: 100
# 连接池中的最大空闲连接
max-idle: 100
# 连接池中的最小空闲连接
min-idle: 100
# 连接池最大阻塞等待时间(使用负值表示没有限制)
max-wait: 60000序列化配置
java
@Configuration
public class RedisTemplateConfiguration {
@Bean
public RedisTemplate<Object, Object> redisTemplate(RedisConnectionFactory redisConnectionFactory) {
RedisTemplate<Object,Object> redisTemplate = new RedisTemplate<>();
redisTemplate.setConnectionFactory(redisConnectionFactory);
//配置序列化规则
Jackson2JsonRedisSerializer jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer(Object.class);
ObjectMapper objectMapper = new ObjectMapper();
objectMapper.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY);
jackson2JsonRedisSerializer.setObjectMapper(objectMapper);
//设置key-value序列化规则
redisTemplate.setKeySerializer(new StringRedisSerializer());
redisTemplate.setValueSerializer(jackson2JsonRedisSerializer);
//设置hash-value序列化规则
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
redisTemplate.setHashValueSerializer(jackson2JsonRedisSerializer);
return redisTemplate;
}
}try-with-resources
在try(...)里声明的资源,会在try-catch代码块结束后自动关闭掉
注意点
实现了AutoCloseable接口的类,在try()里声明该类实例的时候,try结束后自动调用的close方法,这个动作会早于finally里调用的方法
不管是否出现异常,try()里的实例都会被调用close方法
try里面可以声明多个自动关闭的对象,越早声明的对象, 会越晚被close掉
java
try (BufferedReader reader = new BufferedReader(new FileReader("somefile.txt"));
BufferedWriter writer = new BufferedWriter(new FileWriter("outputfile.txt"))) {
String line;
while ((line = reader.readLine()) != null) {
writer.write(line);
// 可能还有一些其他的处理
}
} catch (IOException e) {
// 处理异常
}
// 这里 reader 和 writer 都会自动关闭注册短信验证码防刷方案
需求
一定时间内禁止重复发送短信
两个时间要求
60秒后才可以重新发送短信验证码
发送的短信验证码10分钟内有效
方案:Redis中code存储,基于原先的code拼接时间戳
控制层
匹配上图形验证码后,先删除redis中的旧数据,再发送。
java
@PostMapping("/send_code")
public JsonData sendCode(@RequestBody SendCodeRequest sendCodeRequest, HttpServletRequest request) {
String key = getCaptchaKey(request);
String cacheCaptcha = redisTemplate.opsForValue().get(key);
String captcha = sendCodeRequest.getCaptcha();
if (captcha != null && cacheCaptcha != null && cacheCaptcha.equalsIgnoreCase(captcha)) {
//成功
redisTemplate.delete(key);
JsonData jsonData = notifyService.sendCode(SendCodeEnum.USER_REGISTER, sendCodeRequest.getTo());
return jsonData;
} else {
return JsonData.buildResult(BizCodeEnum.CODE_CAPTCHA_ERROR);
}
}服务层:防刷实现
java
public JsonData sendCode(SendCodeEnum sendCodeEnum, String to) {
String cacheKey = String.format(RedisKey.CHECK_CODE_KEY, sendCodeEnum.name(), to);
String cacheValue = redisTemplate.opsForValue().get(cacheKey);
if (StringUtils.isNotBlank(cacheValue)) {
long ttl = Long.parseLong(cacheValue.split("_")[1]);
//当前时间戳-验证码发送的时间戳,如果小于60秒,则不给重复发送
long leftTime = CommonUtil.getCurrentTimestamp() - ttl;
if (leftTime < (1000 * 60)) {
log.info("重复发送短信验证码,时间间隔:{}秒", leftTime);
return JsonData.buildResult(BizCodeEnum.CODE_LIMITED);
}
}
String code = CommonUtil.getRandomCode(6);
//生成拼接好验证码
String value = code + "_" + CommonUtil.getCurrentTimestamp();
redisTemplate.opsForValue().set(cacheKey, value, CODE_EXPIRED, TimeUnit.MILLISECONDS);
if (CheckUtil.isEmail(to)) {
//发送邮箱验证码 TODO
} else if (CheckUtil.isPhone(to)) {
//发送手机验证码
smsComponent.send(to, smsConfig.getTemplateId(), code);
}
return JsonData.buildSuccess();
}Q: 分库分表下注册的手机号唯一性保证怎么做?
如果允许更换手机号,使用phone作为partitionKey,会触发大量的更新,这个方案不是很好,有没更好的方式
JWT介绍
什么是JWT
JWT 是一个开放标准,它定义了一种用于简洁,自包含的用于通信双方之间以 JSON 对象的形式安全传递信息的方法。 可以使用 HMAC 算法或者是 RSA 的公钥密钥对进行签名
简单来说: 就是通过一定规范来生成token,然后可以通过解密算法逆向解密token,这样就可以获取用户信息
优点
生产的token可以包含基本信息,比如id、用户昵称、头像 等信息,避免再次查库
存储在客户端,不占用服务端的内存资源
缺点
token是经过base64编码,所以可以解码,因此token加密 前的对象不应该包含敏感信息,如用户权限,密码等
如果没有服务端存储,则不能做登录失效处理,除非服务端改秘钥
通常需要判断用户IP和token中的IP是否一致,防止黑产攻击
JWT格式组成:头部、负载、签名
header+payload+signature
头部: 主要是描述签名算法
负载: 主要描述是加密对象的信息,如用户的id等,也可以加些规范里面的东⻄,如iss签发者,exp 过期时间, sub 面向的用户
签名: 主要是把前面两部分进行加密,防止别人拿到token进行base解密后篡改token
关于jwt客户端存储
可以存储在cookie,localstorage和sessionStorage里面
封装生产token方法和校验token方法
java
@Slf4j
public class JWTUtil {
/**
* 主题
*/
private static final String SUBJECT = "forest";
/**
* 加密密钥
*/
private static final String SECRET = "resonance.fun168";
/**
* 令牌前缀
*/
private static final String TOKNE_PREFIX = "dcloud-link";
/**
* token过期时间,7天
*/
private static final long EXPIRED = 1000 * 60 * 60 * 24 * 7;
/**
* 生成token
*
* @param loginUser
* @return
*/
public static String geneJsonWebToken(LoginUser loginUser) {
if (loginUser == null) {
throw new NullPointerException("对象为空");
}
String token = Jwts.builder().setSubject(SUBJECT)
//配置payload
.claim("head_img", loginUser.getHeadImg())
.claim("account_no", loginUser.getAccountNo())
.claim("username", loginUser.getUsername())
.claim("mail", loginUser.getMail())
.claim("phone", loginUser.getPhone())
.claim("auth", loginUser.getAuth())
.setIssuedAt(new Date())
.setExpiration(new Date(CommonUtil.getCurrentTimestamp() + EXPIRED))
.signWith(SignatureAlgorithm.HS256, SECRET).compact();
token = TOKNE_PREFIX + token;
return token;
}
/**
* 解密jwt
* @param token
* @return
*/
public static Claims checkJWT(String token) {
try {
final Claims claims = Jwts.parser().setSigningKey(SECRET)
.parseClaimsJws(token.replace(TOKNE_PREFIX, "")).getBody();
return claims;
} catch (Exception e) {
log.error("jwt 解密失败");
return null;
}
}
}全局登录拦截器
在common模块编写全局拦截器逻辑
java
@Slf4j
public class LoginInterceptor implements HandlerInterceptor {
public static ThreadLocal<LoginUser> threadLocal = new ThreadLocal<>();
@Override
public boolean preHandle(HttpServletRequest request, HttpServletResponse response, Object handler) throws Exception {
// 放行options方法
if(HttpMethod.OPTIONS.name().equalsIgnoreCase(request.getMethod())) {
response.setStatus(HttpStatus.NO_CONTENT.value());
return true;
}
String accessToken = request.getHeader("token");
if (StringUtils.isBlank(accessToken)) {
accessToken = request.getParameter("token");
}
if (StringUtils.isNotBlank(accessToken)) {
Claims claims = JWTUtil.checkJWT(accessToken);
if (claims == null) {
//未登录
CommonUtil.sendJsonMessage(response, JsonData.buildResult(BizCodeEnum.ACCOUNT_UNLOGIN));
return false;
}
long accountNo = Long.parseLong(claims.get("account_no").toString());
String headImg = (String) claims.get("head_img");
String username = (String) claims.get("username");
String mail = (String) claims.get("mail");
String phone = (String) claims.get("phone");
String auth = (String) claims.get("auth");
LoginUser loginUser = LoginUser.builder()
.accountNo(accountNo)
.auth(auth)
.phone(phone)
.headImg(headImg)
.mail(mail)
.username(username)
.build();
//request.setAttribute("loginUser",loginUser);
//通过threadlocal
threadLocal.set(loginUser);
return true;
}
return false;
}
@Override
public void postHandle(HttpServletRequest request, HttpServletResponse response, Object handler, ModelAndView modelAndView) throws Exception {
}
@Override
public void afterCompletion(HttpServletRequest request, HttpServletResponse response, Object handler, Exception ex) throws Exception {
threadLocal.remove();
}
}微服务登录拦截器配置
在微服务模块配置拦截器并引入全局拦截器
java
@Configuration
public class InterceptorConfig implements WebMvcConfigurer {
@Override
public void addInterceptors(InterceptorRegistry registry) {
registry.addInterceptor(new LoginInterceptor())
//添加拦截的路径
.addPathPatterns("/api/account/*/**")
//排除不拦截
.excludePathPatterns(
"/api/account/*/register", "/api/account/*/upload", "/api/account/*/login",
"/api/notify/v1/captcha", "/api/notify/*/send_code");
}
}Q: 这边有个数据库-单表1千万数据,未来1年还会增⻓多500万,性能比较慢,说下你的优化思路
A: 两个角度思考
不分库分表
软优化
数据库参数调优
分析慢查询SQL语句,分析执行计划,进行sql改写和程序改写
优化数据库索引结构
优化数据表结构优化
引入NOSQL和程序架构调整,读写分离
硬优化
提升系统硬件(更快的IO、更多的内存): 带宽、CPU、硬盘
分库分表
根据业务情况而定,选择合适的分库分表策略(没有通用的策略)
外卖、物流、电商领域
先看只分表是否满足业务的需求和未来增⻓
数据库分表能够解决单表数据量很大的时候,数据查询的效率问题
无法给数据库的并发操作带来效率上的提高,分表的实质还是在一个数据库上进行的操作,受数据库IO性能的限制
如果单分表满足不了需求,再分库分表一起
结论
在数据量及访问压力不是特别大的情况,首先考虑缓存、读写分离、索引技术等方案
如果数据量极大,且业务持续增⻓快,再考虑分库分表方案
Mysql数据库分库分表
优点和缺点
优点: 分库分表解决的现状问题
解决数据库本身瓶颈
连接数: 连接数过多时,就会出现‘too many connections’的错误,访问量太大或者数据库设置的最大连接数太小的原因
Mysql默认的最大连接数为100,可以修改,而mysql服务允许的最大连接数为16384
数据库分表可以解决单表海量数据的查询性能问题
数据库分库可以解决单台数据库的并发访问压力问题
解决系统本身IO、CPU瓶颈
磁盘读写IO瓶颈,热点数据太多,尽管使用了数据库本身缓存,但是依旧有大量IO,导致sql执行速度慢
网络IO瓶颈,请求的数据太多,数据传输大,网络带宽不够,链路响应时间变⻓
CPU瓶颈,尤其在基础数据量大单机复杂SQL计算,SQL语句执行占用CPU使用率高,也有扫描行数大、锁冲突、锁等待等原因
缺点: 带来新的问题
问题一: 跨节点数据库Join关联查询和多维度查询
数据库切分前,多表关联查询,可以通过sql join进行实现
分库分表后,数据可能分布在不同的节点上,sql join带来的问题就比较麻烦
不同维度查看数据,利用的partitionKey是不一样的
例如
- 订单表 的partionKey是user_id,用户查看自己的订单列表方便
- 但商家查看自己店铺的订单列表就麻烦,分布在不同数据节点
问题二: 分库操作带来的分布式事务问题
操作内容同时分布在不同库中,不可避免会带来跨库事务问题,即分布式事务
问题三: 执行的SQL排序、翻⻚、函数计算问题
分库后,数据分布再不同的节点上,跨节点多库进行查询时,会出现limit分⻚、order by排序等问题
而且当排序字段非分片字段时,更加复杂了,要在不同的分片节点中将数据进行排序并返回,然后将不同分片返回的结果集进行汇总和再次排序(也会带来更多的CPU/IO资源损耗)
问题四: 数据库全局主键重复问题
常规表的id是使用自增id进行实现,分库分表后,由于表中数据同时存在不同数据库中,如果用自增id,则会出现冲突问题
问题五: 容量规划,分库分表后二次扩容问题
业务发展快,初次分库分表后,满足不了数据存储,导致需要多次扩容
问题六: 分库分表技术选型问题
市场分库分表中间件相对多,框架各有各的优势与短板,应该如何选择
垂直分表: 也就是“大表拆小表”,基于列字段进行的
垂直分库: 针对的是一个系统中的不同业务进行拆分
水平分表: 核心是把一个大表,分割N个小表,每个表的结构是一样的,数据不一样,全部表的数据合起来就是全部数据
水平分库: 水平分库是把不同表拆到不同数据库中,它是对数据行的拆分,不影响表结构
动态指定sharding jdbc 的雪花算法中的属性work.id属性
要百分百避免雪花算法中的workid重复,则需要动态指定sharding jdbc的雪花算法中的属性work.id属性,通过调用System.setProperty()的方式实现,可用容器的 id 或者机器标识位
java
@Configuration
public class SnowFlakeWordIdConfig {
/**
* 动态指定sharding jdbc 的雪花算法中的属性work.id属性
* 通过调用System.setProperty()的方式实现,可用容器的 id 或者机器标识位
* workId最大值 1L << 100,就是1024,即 0<= workId < 1024
* {@linkSnowflakeShardingKeyGenerator#getWorkerId()}
*/
static {
try {
InetAddress ip4 = Inet4Address.getLocalHost();
String hostAddress = ip4.getHostAddress();
String workId = Math.abs(hostAddress.hashCode() % 1024) + "";
System.setProperty("workId", workId);
} catch (UnknownHostException e) {
throw new BizException(BizCodeEnum.OPS_NETWORK_ADDRESS_ERROR);
}
}
}配置文件中使用
shell
id: ${workId}时间回拨可能导致雪花算法ID重复,在sharing-jdbc 4已经解决
利用雪花算法生成唯一ID
java
public class IDUtil {
private static SnowflakeShardingKeyGenerator shardingKeyGenerator = new SnowflakeShardingKeyGenerator();
/**
* 雪花算法生成器
* @return
*/
public static Comparable<?> geneSnowFlakeID() {
return shardingKeyGenerator.generateKey();
}
}敏感数据+自增ID暴露的商业秘密
什么是数据脱敏
也叫数据的去隐私化,在给定脱敏规则和策略的情况下,对敏感数据比如 手机号、身份证 等信息,进行转换或者修改的一种技术手段,防止敏感数据直接在不可靠的环境下使用和泄露、撞库等。
数据库业务规则安全:自增ID暴露的商业秘密
背景
作为后端开发人员肯定离不开数据库设计,尽管你知道数据安全、接口安全、网络安全,但你也很大可能不小心暴露的公司的核心机密。
【做空上市公司的股票】如果你有炒股,那你知道如果这个数据库设计漏洞被他人知道,就可以做空一个上司公司的股票的不?
【摧毁对手的利器】如果一个公司在是靠业务数据来说话的,如果被他人知道,在核心的时间点,被披露出来,那融资可能凉凉,企业可能面临倒闭。
结语
合格的架构,不单止某个技术厉害,更要考虑和业务-商业上的结合。
正常的业务表,会用自增id,但是也会加个业务id,如果有关联,则用 biz_id进行关联并返回
其实最靠谱的就是,不要把有业务规则的id暴露给用户,不止id字段,类似的敏感字段都是
Q: 为什么要用62进制转换,不是64进制?
62进制转换是因为62进制转换后只含数字+小写+大写字母
而64进制转换会含有/、+这样的符号(不符合正常URL的字符)
10进制转62进制可以缩短字符,如果我们要6位字符的话,已经有560亿个组合了
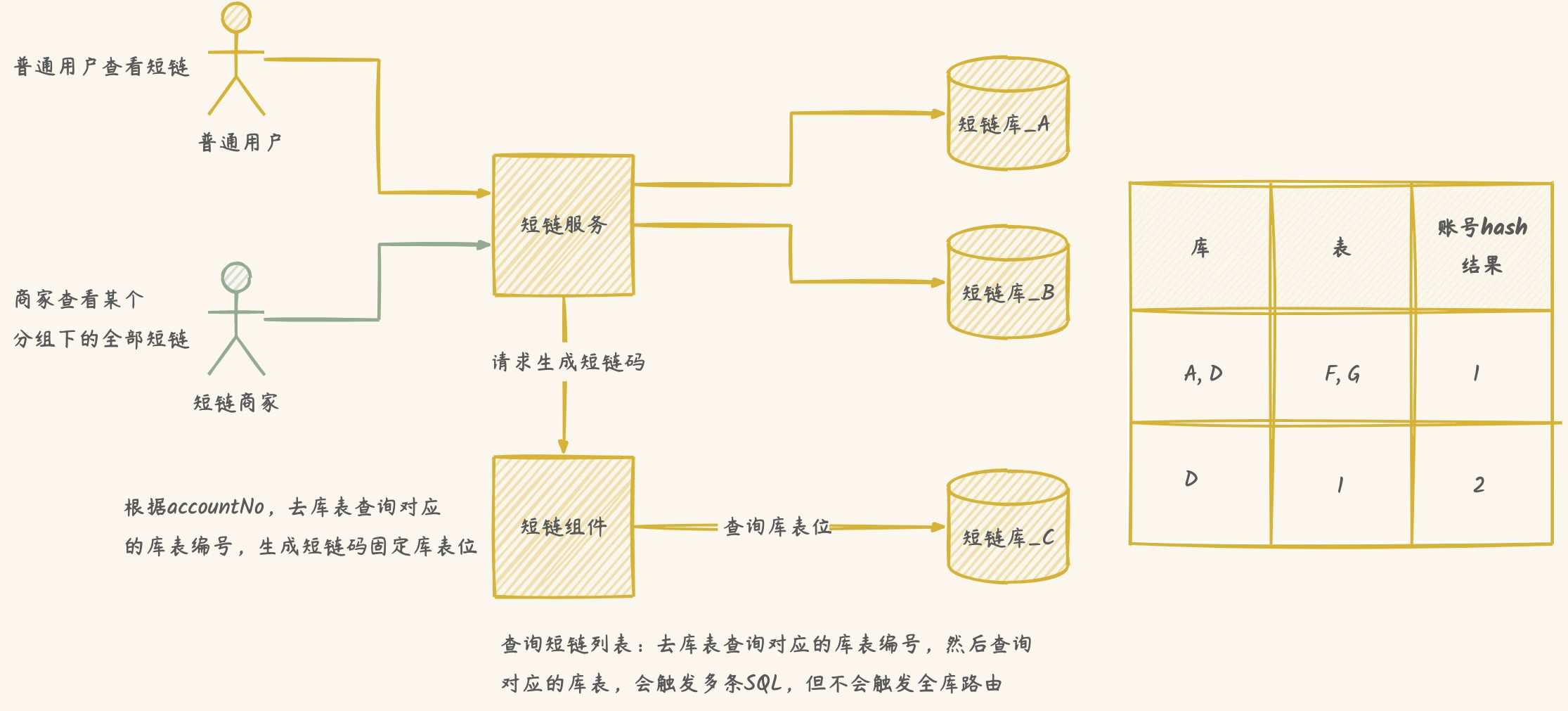
分库分表多维度查询解决方案
字段解析配置
code存储格式:库位+短链码+表位
业务量超过评估量,分库分表-二次扩容的时候避免数据迁移
不用一次性建立很多个库表,可以动态添加,节省服务器资源
NOSQL
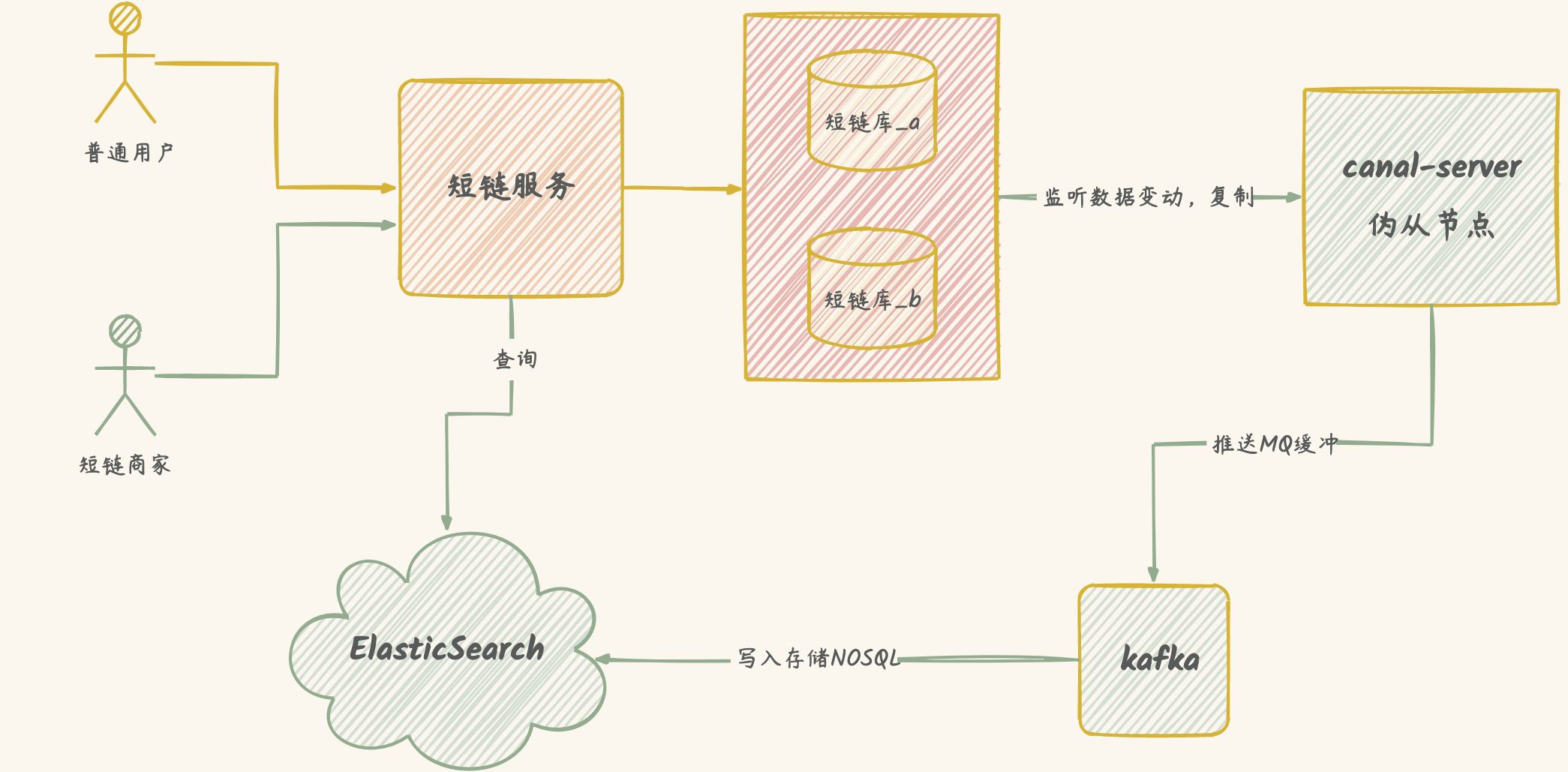
冗余双写方案
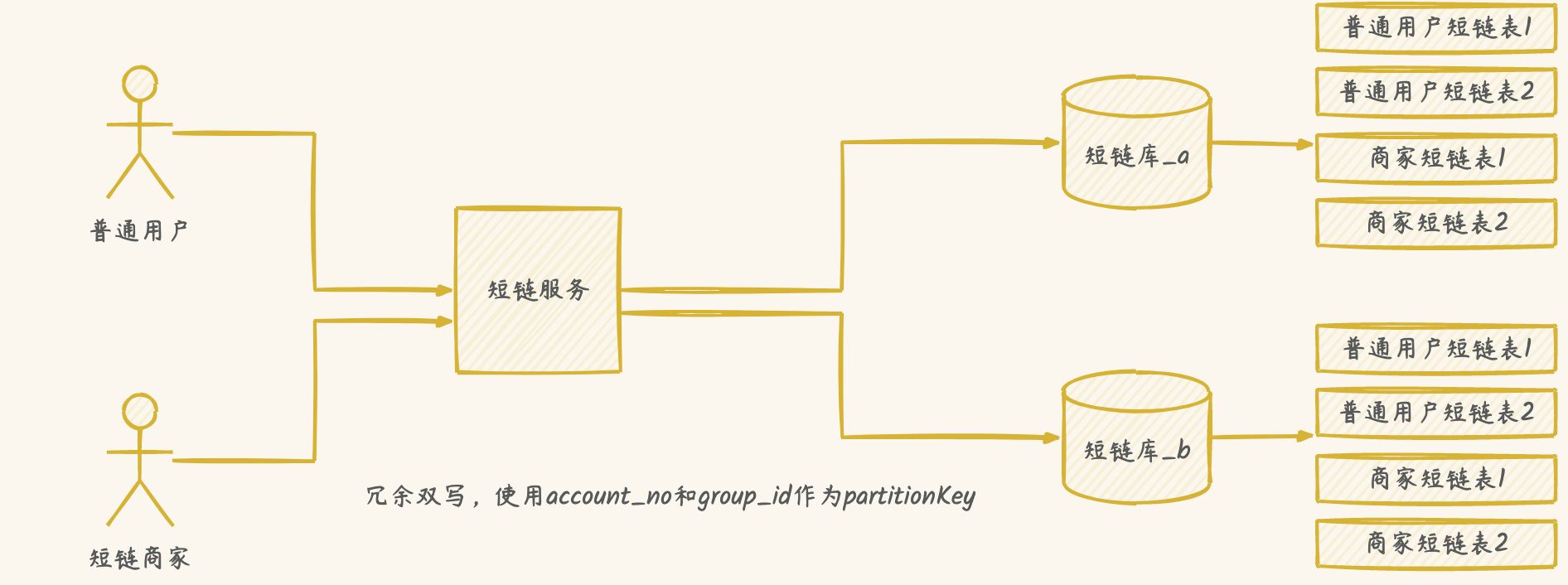
缺点:并发事物带来性能问题
优化解决方案
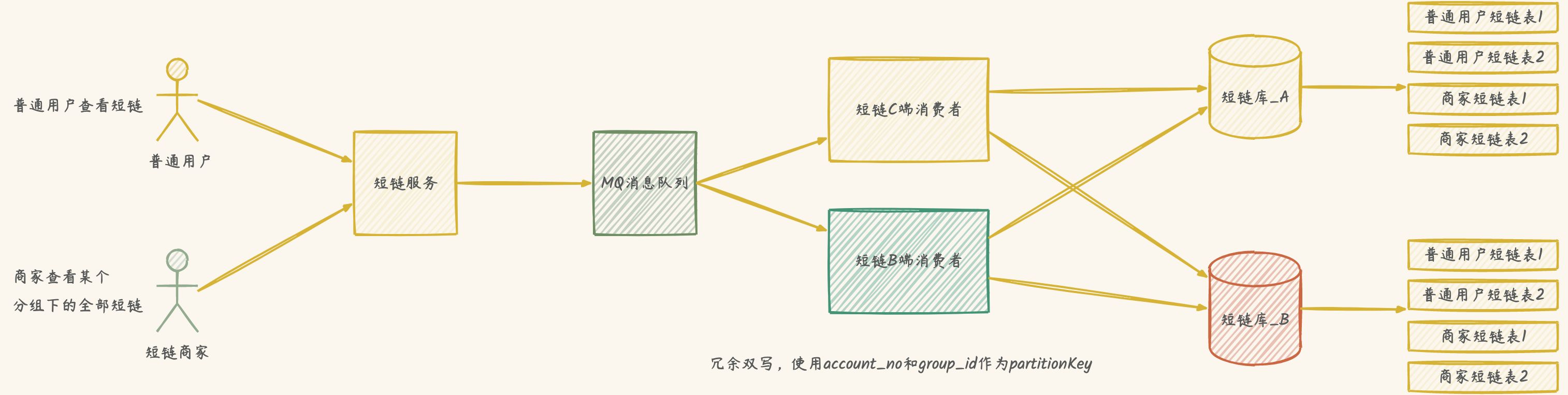
数据库表负载均衡
使用加权库表位算法,解决扩容后数据倾斜不均匀问题
数据库权重算法
java
public class ShardingDBConfig {
/**
* 存储数据库位置编号
*/
private static final List<Map<String, String>> dbPrefixList = new ArrayList<>();
private static final Random random = new Random();
//配置启用那些库的前缀
static {
dbPrefixList.add(Map.of("value", "0", "weight", "1"));
dbPrefixList.add(Map.of("value", "1", "weight", "2"));
dbPrefixList.add(Map.of("value", "a", "weight", "6"));
}
private static int getTotalWeight() {
int totalWeight = 0;
for (Map<String, String> item : dbPrefixList) {
int weight = Integer.parseInt(item.get("weight"));
totalWeight += weight;
}
return totalWeight;
}
/**
* 获取随机的前缀
* 根据权重获取value,负载均衡
*
* @return
*/
public static String getRandomDBPrefix() {
int totalWeight = getTotalWeight();
int randomIndex = -1;
int randomNum = random.nextInt(totalWeight);
for (int i = 0; i < dbPrefixList.size(); i++) {
int weight = Integer.parseInt(dbPrefixList.get(i).get("weight"));
// 权重越大,被减去小于0的可能性更大
randomNum -= weight;
if (randomNum < 0) {
randomIndex = i;
break;
}
}
return dbPrefixList.get(randomIndex).get("value");
}
}数据表权重算法
java
public class ShardingTableConfig {
/**
* 存储数据表位置编号
*/
private static final List<Map<String, String>> tableSuffixList = new ArrayList<>();
private static final Random random = new Random();
// 配置启用哪些表的后缀
static {
tableSuffixList.add(Map.of("value", "0", "weight", "1"));
tableSuffixList.add(Map.of("value", "a", "weight", "3"));
}
private static int getTotalWeight() {
int totalWeight = 0;
for (Map<String, String> item : tableSuffixList) {
int weight = Integer.parseInt(item.get("weight"));
totalWeight += weight;
}
return totalWeight;
}
/**
* 获取随机的后缀
*
* @return
*/
public static String getRandomTableSuffix() {
int totalWeight = getTotalWeight();
int randomIndex = -1;
int randomNum = random.nextInt(totalWeight);
for (int i = 0; i < tableSuffixList.size(); i++) {
int weight = Integer.parseInt(tableSuffixList.get(i).get("weight"));
randomNum -= weight;
if (randomNum < 0) {
randomIndex = i;
break;
}
}
return tableSuffixList.get(randomIndex).get("value");
}
}创建短链关键代码
java
public String createShortLinkCode(String originalUrl) {
long murmur32 = CommonUtil.murmurHash32(originalUrl);
//转62进制
String code = encodeToBase62(murmur32);
String shortLinkCode = ShardingDBConfig.getRandomDBPrefix() + code + ShardingTableConfig.getRandomTableSuffix();
return shortLinkCode;
}RabbitMQ
选择RabbitMQ理由
业务开发团队本身熟悉RabbitMQ(对内,省了学习成本、运维成本、现有基础设施)
RabbitMQ自带延迟队列,更适合业务这块,比如定时任务、分布式事务处理
Kafka比较适合在大数据领域流式计算
RoutingKey和BindingKey的作用
区别发送的绑定的概念
routingKey 是发送时用,细化到具体名称
bindingKey 是绑定时使用,通常包含通配符
MQ不会自动创建队列解决方案
懒加载:@Bean+@RabbitListener
没有@Bean,用queuesToDeclare也会自动创建
java
@RabbitListener(queuesToDeclare = { @Queue("short_link.add.link.queue") })MQ冗余双写带来的问题
短链码是哪里生成的?生产者端还是消费者端?
短链码重复了怎么办?
生产者端生成,怎么保证短链码发送前、消费后一致性?
消费者端生成,B端和C端并非同时插入,怎么保证短链码一致性?
解决方案:分布式重入锁
先判断是否有,如没这个key,则设置key-value,配置过期时间,加锁成功
如果有同个key,则判断value是否为同一个账号,如果是则返回加锁成功
如果不是同个账号则加锁失败
解决方式,配置key过期时间久点,比如2~5天
以下情况会发生队列转发
延迟队列
未被消费并且超时后转发的队列
消息消费超过一定重试次数(需要改为自动ack确认消息)
队列超过长度
防重提交注解实现
元注解:注解的注解
元注解定义
java
@Documented
@Target(ElementType.METHOD)
@Retention(RetentionPolicy.RUNTIME)
public @interface RepeatSubmit {
/**
* 防重复提交,支持两种,一个是方法参数,一个是令牌
*/
enum Type {PARAM, TOKEN}
/**
* 防重复提交方式,默认是方法参数
* @return
*/
Type limitType() default Type.PARAM;
/**
* 加锁过期时间,默认是5秒
* @return
*/
long lockTime() default 5;
}@Documented 可以在 doc 中使用注解
@Target(ElementType.METHOD) 可以在方法上使用注解
@Retention(RetentionPolicy.RUNTIME) 在运行时作用,可以用反射获取类
注解切面类实现
java
@Aspect
@Component
@Slf4j
public class RepeatSubmitAspect {
@Autowired
private StringRedisTemplate redisTemplate;
@Autowired
private RedissonClient redissonClient;
/**
* 定义 @Pointcut注解表达式,
* 方式一:@annotation:当执行的方法上拥有指定的注解时生效(我们采用这)
* 方式二:execution:一般用于指定方法的执行
*/
@Pointcut("@annotation(repeatSubmit)")
public void pointCutNoRepeatSubmit(RepeatSubmit repeatSubmit) {
}
/**
* 环绕通知, 围绕着方法执行
*
* @param joinPoint
* @param repeatSubmit
* @return
* @throws Throwable
* @Around 可以用来在调用一个具体方法前和调用后来完成一些具体的任务。
* <p>
* 方式一:单用 @Around("execution(* net.xdclass.controller.*.*(..))")可以
* 方式二:用@Pointcut和@Around联合注解也可以(我们采用这个)
* <p>
* <p>
* 两种方式
* 方式一:加锁 固定时间内不能重复提交
* <p>
* 方式二:先请求获取token,这边再删除token,删除成功则是第一次提交
*/
@Around("pointCutNoRepeatSubmit(repeatSubmit)")
public Object around(ProceedingJoinPoint joinPoint, RepeatSubmit repeatSubmit) throws Throwable {
HttpServletRequest request = ((ServletRequestAttributes) RequestContextHolder.getRequestAttributes()).getRequest();
long accountNo = LoginInterceptor.threadLocal.get().getAccountNo();
//用于记录成功或者失败
boolean res = false;
//防重提交类型
String type = repeatSubmit.limitType().name();
if (type.equalsIgnoreCase(RepeatSubmit.Type.PARAM.name())) {
//方式一,参数形式防重提交
long lockTime = repeatSubmit.lockTime();
String ipAddr = CommonUtil.getIpAddr(request);
MethodSignature methodSignature = (MethodSignature) joinPoint.getSignature();
Method method = methodSignature.getMethod();
String className = method.getDeclaringClass().getName();
String key = "order-service:repeat_submit:" + CommonUtil.MD5(String.format("%s-%s-%s-%s", ipAddr, className, method, accountNo));
// 加锁
// redisTemplate.opsForValue().setIfAbsent(key, "1", lockTime, TimeUnit.SECONDS);
RLock lock = redissonClient.getLock(key);
// 尝试加锁,最多等待0秒,上锁以后5秒自动解锁 [lockTime默认为5s, 可以自定义]
res = lock.tryLock(0, lockTime, TimeUnit.SECONDS);
} else {
//方式二,令牌形式防重提交
String requestToken = request.getHeader("request-token");
if (StringUtils.isBlank(requestToken)) {
throw new BizException(BizCodeEnum.ORDER_CONFIRM_TOKEN_EQUAL_FAIL);
}
String key = String.format(RedisKey.SUBMIT_ORDER_TOKEN_KEY, accountNo, requestToken);
/**
* 提交表单的token key
* 方式一:不用lua脚本获取再判断,之前是因为 key组成是 order:submit:accountNo, value是对应的token,所以需要先获取值,再判断
* 方式二:可以直接key是 order:submit:accountNo:token,然后直接删除成功则完成
*/
res = redisTemplate.delete(key);
}
if (!res) {
throw new BizException(BizCodeEnum.ORDER_CONFIRM_REPEAT);
}
log.info("环绕通知执行前");
Object obj = joinPoint.proceed();
log.info("环绕通知执行后");
return obj;
}
}@Aspect 定义这是一个切面类
@Component 加入 SpringBoot 容器
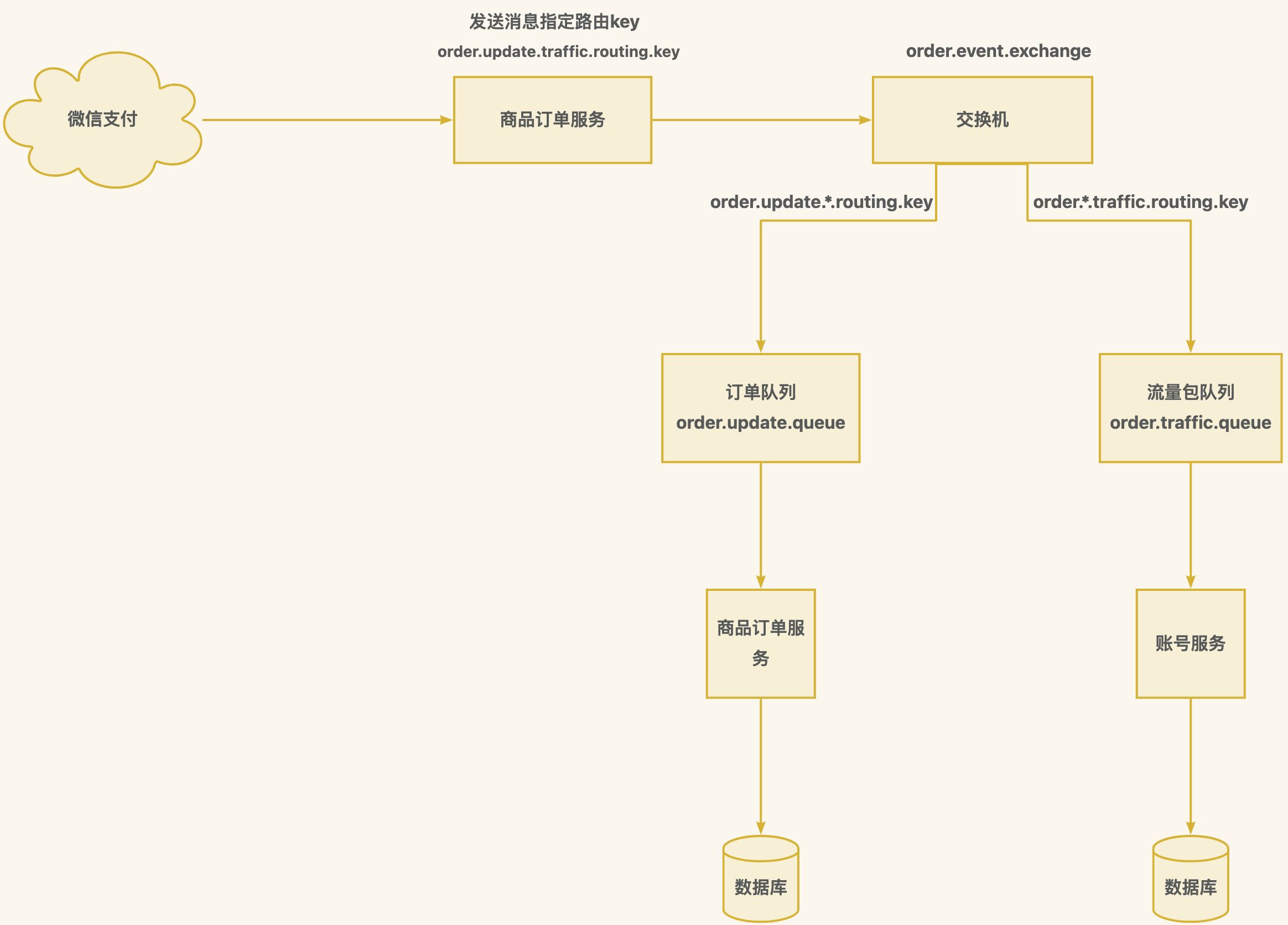
订单更新和流量包权益更新
不推荐同步调用,造成高并发性能问题和分布式事务问题
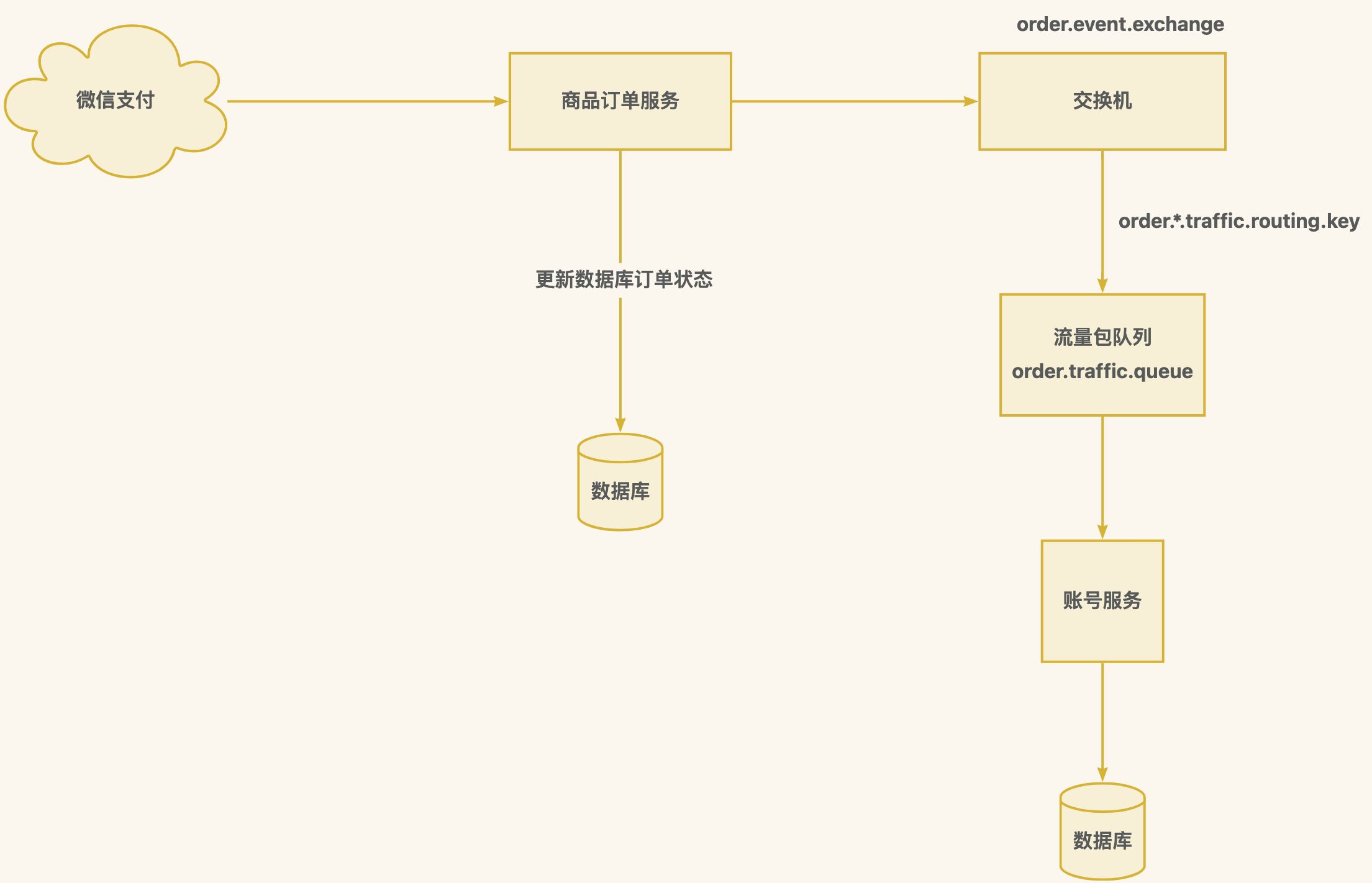
方案一:直接进入队列冗余双写,然后响应微信支付接口,再消费消息-更新数据库订单状态和发放流量包
方案二:折中方案,接收微信回调通知更新数据库,发送新增流量包 MQ 消息,响应微信,再消费流量包消息
高并发下扣减流量包解决方案-通用秒杀
如果创建短链加上rpc调用扣减流量包接口,性能是非常差的
解决方案
使用预扣减,存入redis中,key的过期时间刚好是流量包的过期时间。
第一次redis中没有key,则一定有免费流量包,直接创建短链,然后在消费端消费后存入当前剩余流量包到redis中
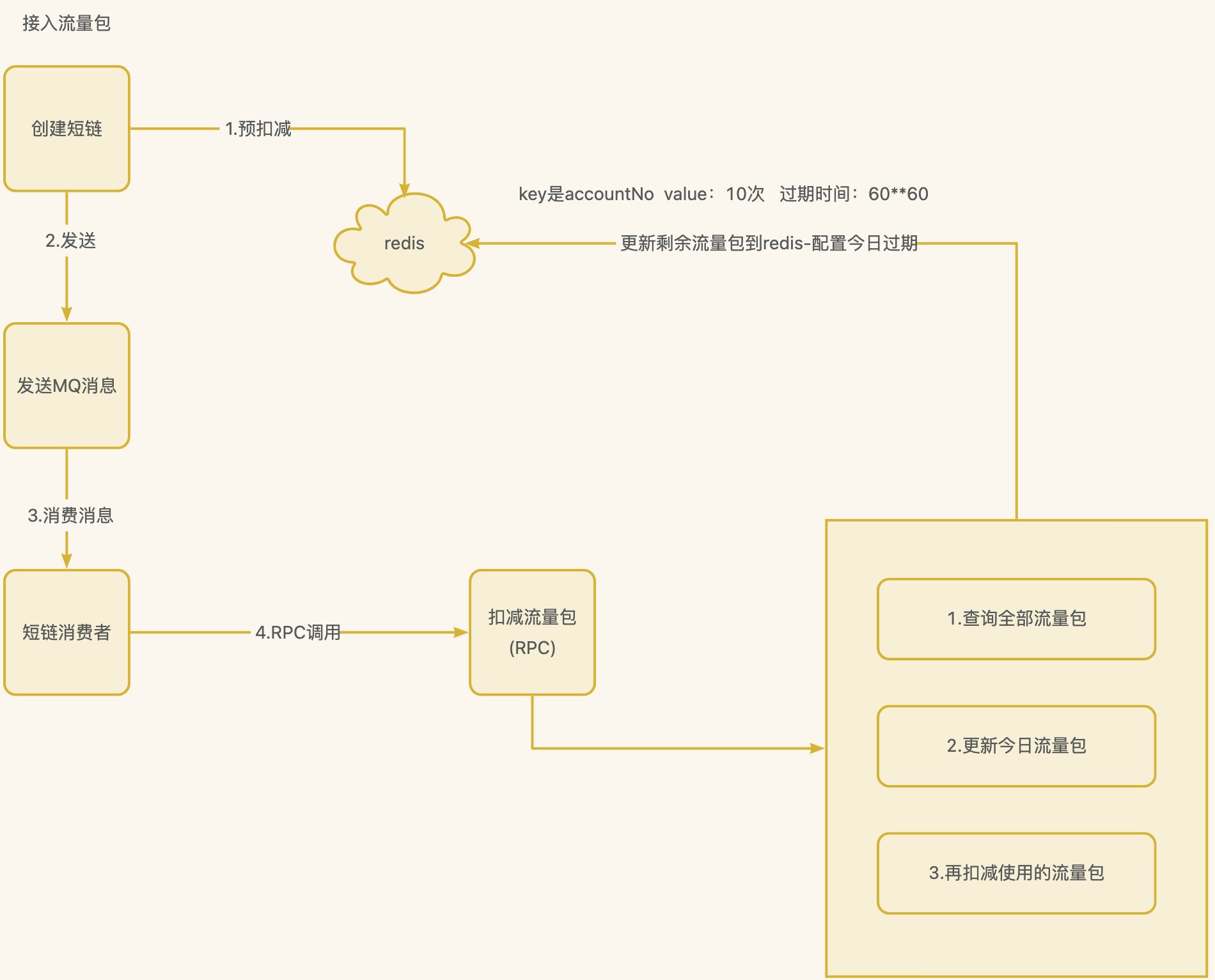
流量包服务
流量包订单不是用户经常关注的,因此并发量不高,只需要分表避免单表数据过多
订单下单模块链路流程分析
防重提交(重点)
服务端token令牌
AOP+自定义注解
获取最新的流量包价格
订单验价
如果有优惠券或者其他抵扣
验证前端显示和后台计算价格
创建订单对象保存数据库
发送延迟消息-用于自动关单(重点)
创建支付信息-对接三方支付(重点)
回调更新订单状态(重点)
支付成功创建流量包(重点)
支付平台使用非对称加密算法
一套或者两套RSA加密都可以,具体看平台机制。
一套
应用用私钥加密发送,支付平台用公钥解密
支付平台用公钥加密发送,应用用私钥解密
两套公钥和私钥
应用给支付平台发送信息一套,支付平台给应用发送(回调)信息一套
两套RSA加密
一套用于保证统一下单时的信息安全
另一套用于保证支付平台回调时的信息安全
AOP
能否解释下AOP里面常⻅的概念,比如 横切、通知、连接点、切入点、切面 ?
横切关注点
对哪些方法进行拦截,拦截后怎么处理,这些就叫横切关 注点
比如 权限认证、日志、事物
通知 Advice
在特定的切入点上执行的增强处理
做啥? 比如你需要记录日志,控制事务 ,提前编写好通用 的模块,需要的地方直接调用
比如重复提交判断逻辑
类型
@Before前置通知
在执行目标方法之前运行
@After后置通知
在目标方法运行结束之后
@AfterReturning返回通知
在目标方法正常返回值后运行
@AfterThrowing异常通知
在目标方法出现异常后运行
@Around环绕通知
在目标方法完成前、后做增强处理 ,环绕通知是最重要的通知类型 ,像事务,日志等都是环绕通知,注意编 程中核心是一个ProceedingJoinPoint,需要手动执行 joinPoint.procced()
连接点 JointPoint
要用通知的地方,业务流程在运行过程中需要插入切面的具体位置,
一般是方法的调用前后,全部方法都可以是连接点
只是概念,没啥特殊
切入点 Pointcut
不能全部方法都是连接点,通过特定的规则来筛选连接点, 就是Pointcut,选中那几个你想要的方法
在程序中主要体现为书写切入点表达式(通过通配、正则 表达式)过滤出特定的一组 JointPoint连接点
过滤出相应的 Advice 将要发生的joinpoint地方
切面 Aspect
通常是一个类,里面定义 切入点+通知 , 定义在什么地方; 什么时间点、做什么事情
通知 advice指明了时间和做的事情(前置、后置等)
切入点 pointcut 指定在什么地方干这个事情
web接口设计中,web层->网关层->服务层->数据层,每一 层之间也是一个切面,对象和对象,方法和方法之间都是一个个切面
目标 target
目标类,真正的业务逻辑,可以在目标类不知情的条件下,增加新的功能到目标类的链路上
织入 Weaving
把切面(某个类)应用到目标函数的过程称为织入
密码学
对称加密
加密和解密是用的同一个
常见算法
DES(已被破解)
3DES(暂时未被破解)
AES
优点
操作简单,加密快,密钥简单
缺点
密钥一旦被窃取,信息会暴露,安全性不高
非对称加密
A要向B发送消息,那么B首先用RSA算法生成一个密钥对,然后把私钥自己存储,把公钥发送给A
发送方通过公钥加密,接收方通过密钥解密
常见算法
RSA
DSA
ECC
优点
安全性高
缺点
加密较慢,时间长,只适合对少量数据进行加密
Hash算法-单项加密
无法被解密,只有重新输入明文,经过hash算法加密得到相同的密文,才算解密
常见算法
MD5
彩虹表暴力破解www.cmd5.com
SHA1
SHA224
SHA256
优点
快速计算,具有单向性,不可通过散列值推出原消息
场景
文件完整性校验(Checksum)算法、常规加密等
密码存储常用方式
双重MD5
MD5加盐
双重MD5+加盐
为什么不用最强的算法?
更安全的算法,加密解密更复杂,接口性能下降更严重
对称加密和非对称加密混合使用的例子
前面通信使用非对称加密,发送方和接收方都得到相同的口令之后,后续通信使用对称加密,密钥就是口令
应用场景
HTTPS
HTTPS非对称加密只作用在证书验证阶段
内容传输加密使用的是对称加密
既保证了密钥的安全性,又保证了后续数据传输的数据加解密的性能
微信支付
设计模式
软件设计开发原则
(SOLID原则)
单一职责原则
开闭原则
对扩展开放,对修改关闭
里氏替换原则LSP
在程序中尽量使用基类类型来对对象进行定义
依赖倒转原则
是开闭原则的基础,针对接口编程,依赖于抽象而不依赖于具体
高层模块不应该依赖低层模块,二者都应该依赖其抽象
接口隔离原则
客户端不应该依赖那些它不需要的接口
使用多个隔离的接口,比使用单个接口要好,降低类之间的耦合度
迪米特法则
最少知道原则,一个实体应当尽量少地与其他实体之间发生相互作用,使得系统功能模块相对独立
工厂模式
简单工厂模式
又称静态工厂方法, 可以根据参数的不同返回不同类的实例, 专⻔定义一个类来负责创建其他类的实例,被创建的实例通常都具有共同的父类
优点
将对象的创建和对象本身业务处理分离可以降低系统的耦合度,使得两者修改起来都相对容易。
缺点
工厂类的职责相对过重,增加新的产品需要修改工厂类的判断逻辑,这一点与开闭原则是相违背
将会增加系统中类的个数,在一定程度上增加了系统的复杂度和理解难度,不利于系统的扩展和维护
工厂方法模式
通过实现类实现相应的方法来决定相应的返回结果,这种方式的可扩展性比较强;
抽象工厂模式
基于上述两种模式的拓展,且支持细化产品
策略模式
定义一系列的算法,把它们一个个封装起来, 并且使它们可相互替换
⻆色
Context上下文:屏蔽高层模块对策略、算法的直接访问,封装可能存在的变化
Strategy策略⻆色:抽象策略⻆色,是对策略、算法家族的抽象,定义每个策略或算法必须具有的方法和属性
ConcreteStrategy具体策略⻆色:用于实现抽象策略中的操作,即实现具体的算法
单例模式
懒汉方式
延迟创建对象
优点
前期不占用内存,用时才创建
缺点
初次创建时有延迟
饿汉方式
提前创建好对象
优点
实现简单,使用时没延迟
缺点
instance会一直占用内存
如何选择
如果对象不大,且创建对象不复杂,直接使用饿汉方式即可
其他情况则使用懒汉实现方式
微信支付回调验签流程
获取报文
验证签名(确保是微信传输过来的)
解密(AES对称解密出原始数据)
处理业务逻辑
响应请求
账号服务
新用户注册拉新赠送免费流量包方案
新用户注册直接主逻辑返回成功
发送MQ消息发放新用户注册权益
MQ保证幂等性
付费流量包唯一索引:accountNo+outTradeNo
免费流量包唯一索引:accountNo+free_init
过期的流量包删除
直接使用物理删除,避免数据过多
数据过多,删除较慢,使用分布式调度XXL-Job
XXL-Job
为什么选择xxl-job
xxl-job使用简单,上手较快
基本满足业务需求
团队里大部分人都熟悉
用户每天都有免费的流量包,怎么维护?
采用惰性更新,用户用的时候再更新即可
更进阶的
定时+惰性
把每日或每周活跃的用户单独拿出来,更新定时流量包,避免数据更新太多造成延迟
用户用时再更新
Redis过期key淘汰机制
定期删除
隔一段时间就随机抽取一些设置了过期时间的key,判断是否过期,如果过期就删除
定期删除可能导致很多过期的key到了时间并没有被删除
惰性删除
当客户端试图访问key时,发现该key已超时会把此key从内存中删除
分布式事务
一个操作单元,所有操作最终要保持一致,要么全部成功,要么全部失败
本地事物
数据库提供的
分布式事务
分布式系统各个节点上的不同数据库的一致性
分类
刚性事务
遵循ACID
柔性事务
遵循BASE理论
关于数据一致性
强一致
操作后立马一致且可以访问
弱一致
容忍部分或全部访问不到
最终一致
弱一致性经过一段时间后,都一致且正常
短链平台数据可视化-埋点采集
常⻅数据埋点采集方案介绍
大数据-ETL和数据仓库建设分层
ETL(Extract-Transform-Load)
抽取(extract)、转换(transform)、加载(load)
数仓分层介绍
顺序
ODS: 原始数据层
- 汇集多个原始未处理的数据
DWD: 明细数据层
- 清洗数据:比如脱敏、去除脏数据
DWM: 数据中间层
- 数据通用维度聚合操作:比如地理位置、设备
DWS: 数据服务层
- 分组聚合:比如某个商品xx秒内多少个pv、uv
ADS: 数据应用层
- 提供给数据产品和数据分析使用的数据
为什么要分层
开发者都希望自己的数据能够有顺序地流转,方便排查问题
复杂问题简单化
- 复杂任务分层处理,每层定位职责不一样,每个层只解决特定的问题
- 减少重复开发量
- 规范数据分层,开发通用的中间层,可以极大地减少重复计算的工作
总结: 提效+懒人的智慧,主要是增加数据计算的复用性,每次新增加统计需求时,不用从原始数据进行计算,而是从半成品继续加工,从而更快更省成本
埋点方式
代码埋点
通过代码进行控制
可视化埋点
通过采集SDK
全埋点|无埋点
短链平台采用方式
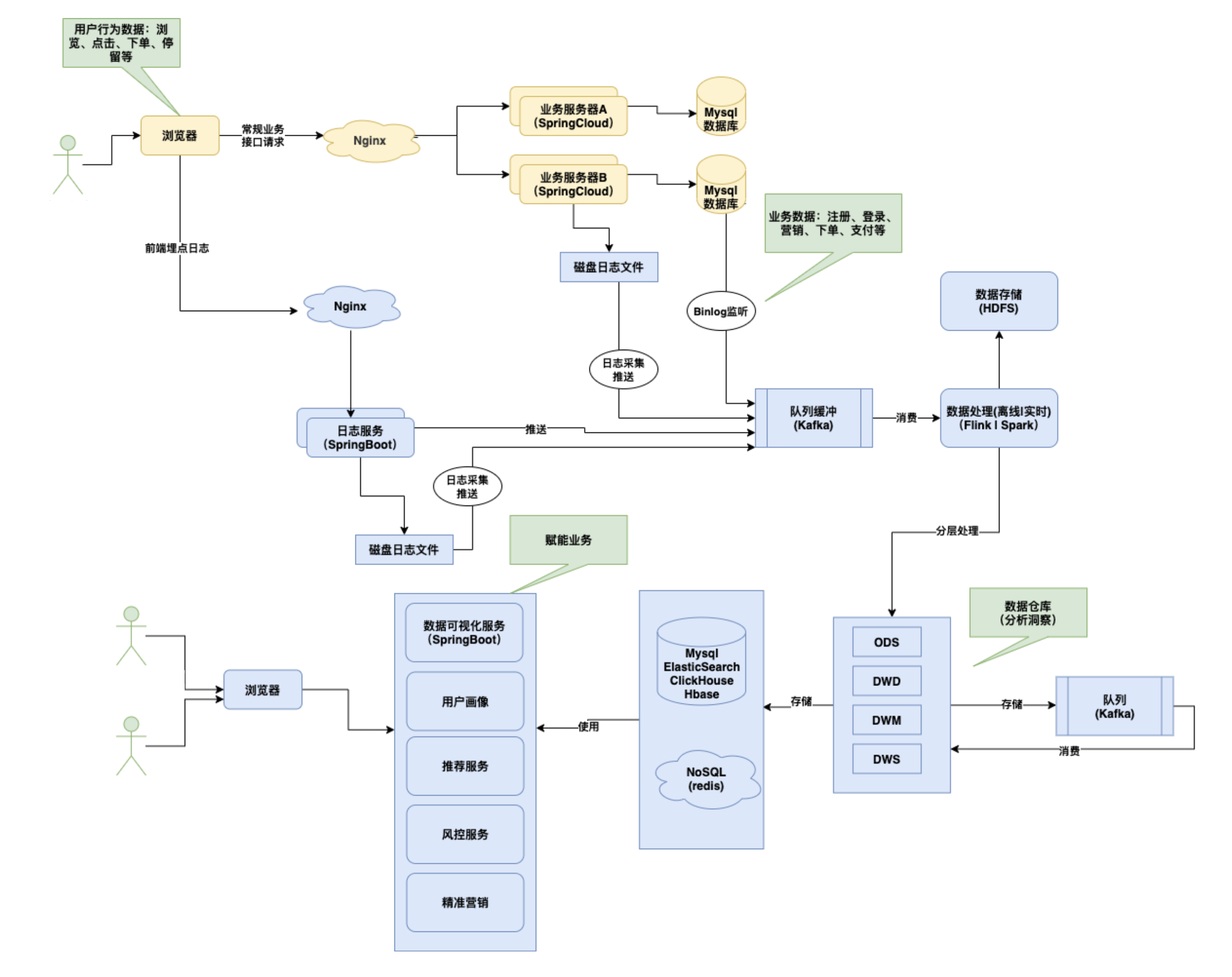
访问短链码
记录日志-打印控制台(方便排查)
发送Kafka(本身异步发送)
数仓
度量值
站在维度的⻆度去看事实表,看事实表的度量值
维度表
维度表就是【你观察该事物的⻆度,是从哪个⻆度去观察这个内容的,商品⻆度,地区⻆度等】
事实表
事实表就是你要关注的内容
总结
维度是维度建模的基础和灵魂。在维度建模中,将度量称为“事实” , 将环境描述为“维度”。
宽表(明细表)
缺点:数据的大量冗余
优点:减少表关联数量,查询性能的提高,空间换时间
窄表
缺点:做数据分析查询OLAP时,需要大量关联多个表,性能下降
优点: 存储省空间,大量数据只存储某个表
数仓建模
(类似数据库建表)
OLTP中: Mysql数据库建表,表和表之间的关系模型,叫关系建模
OLAP中: 根据一个事实表为中心进行建表,面向业务分析为主,叫维度建模
高频面试题-如何突破微信支付统一下单600QPS
多商户策略,采用负载均衡方式进行操作
详细:记录好用户下单所用的商户信息,也可以预先绑定好
准备5个商户号, 用户下单根据用户id取模是采用哪个商户进行调用
统一下单、退款、查询订单状态等就能分摊瞬时压力,也是固定到使用对应的商户进行操作
根据API进行控制好频率+监控
注意:秒杀类业务,常规都是高并发锁定库存生成订单,然后支付是可以靠前端⻚面做离散支付的一定时间内错峰
Ip解析地理位置信息也是类似的
对接多个高德账号或者对接多个在线解析平台,比如百度、高德、腾讯等
做好统一的地理位置信息编码即可
跨域
浏览器从一个域名的网⻚去请求另一个域名的资源时,域名、端口、协议任一不同,都是跨域。
需要解决跨域,有多种配置
Nginx配置
业务微服务配置
前端Node层渲染
Gateway配置
java
@Configuration
public class CorsConfig {
@Bean
public WebFilter corsFilter() {
return (ServerWebExchange ctx, WebFilterChain chain) -> {
ServerHttpRequest request = ctx.getRequest();
if (CorsUtils.isCorsRequest(request)) {
HttpHeaders requestHeaders = request.getHeaders();
ServerHttpResponse response = ctx.getResponse();
HttpMethod requestMethod = requestHeaders.getAccessControlRequestMethod();
HttpHeaders headers = response.getHeaders();
headers.add(HttpHeaders.ACCESS_CONTROL_ALLOW_ORIGIN, requestHeaders.getOrigin());
headers.addAll(HttpHeaders.ACCESS_CONTROL_ALLOW_HEADERS,
requestHeaders.getAccessControlRequestHeaders());
if (requestMethod != null) {
headers.add(HttpHeaders.ACCESS_CONTROL_ALLOW_METHODS, requestMethod.name());
}
headers.add(HttpHeaders.ACCESS_CONTROL_ALLOW_CREDENTIALS, "true");
headers.add(HttpHeaders.ACCESS_CONTROL_EXPOSE_HEADERS, "*");
if (request.getMethod() == HttpMethod.OPTIONS) {
response.setStatusCode(HttpStatus.OK);
return Mono.empty();
}
}
return chain.filter(ctx);
};
}
}DevOps
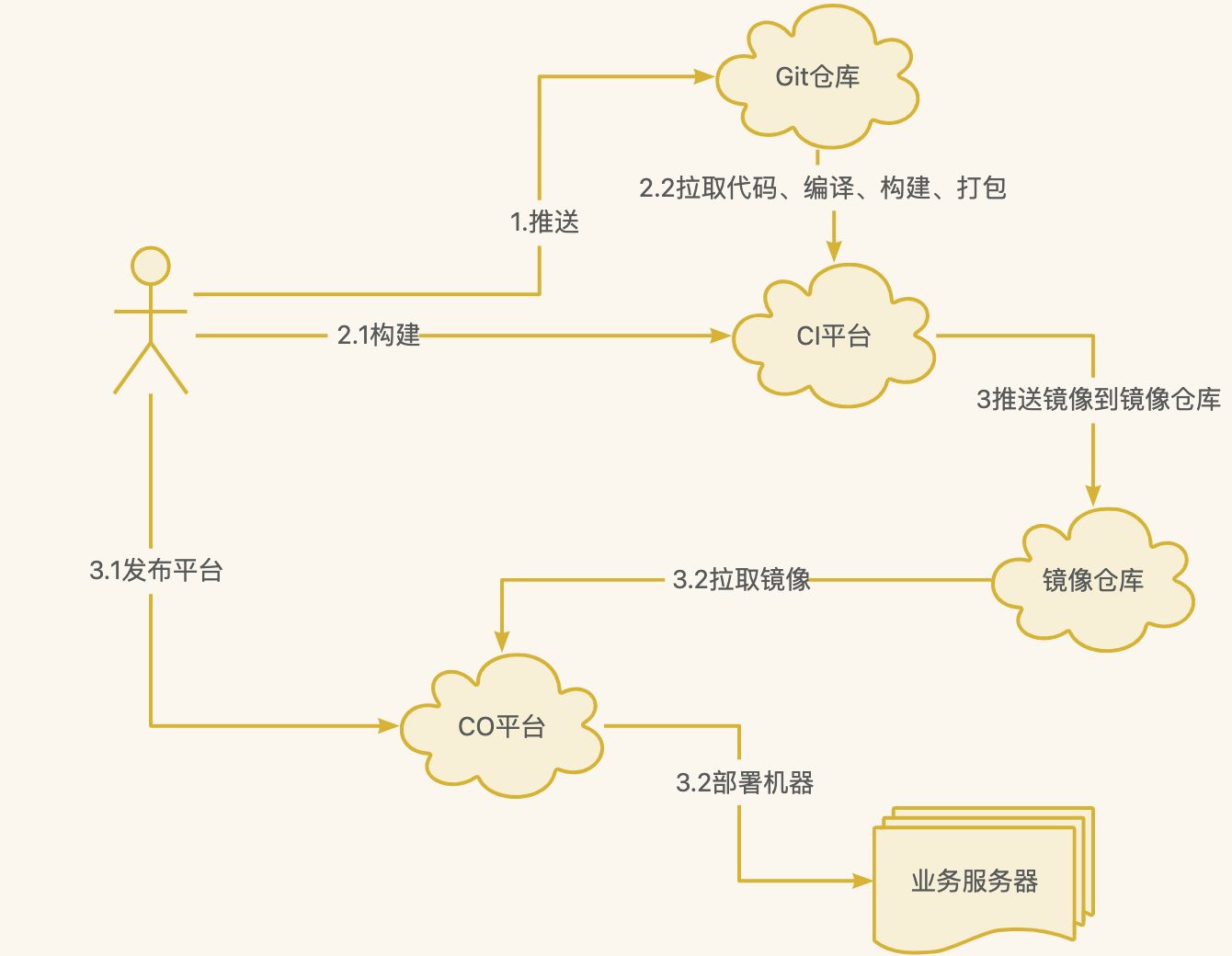
DevOps一词是由英文 Development(开发) 和 Operations(运维) 组合而成
一种思想,强调软件开发测试运维的一体化,减少各个部⻔之间的沟通成本从而实现软件的快速高质量的发布
DevOps与CICD紧密相关,DevOps要实现人员一体化,须要借助CICD工具来自动化整个流程
CICD
是指持续集成、持续发布,是一套实现软件的构建测试部署的自动化流程。
Docker 安装
先安装yml
java
yum install -y yum-utils device-mapper-persistent-data lvm2设置阿里云镜像
java
sudo yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo查看可安装的docker版本
java
yum list docker-ce --showduplicates | sort -r安装docker
java
yum -y install docker-ce-20.10.10-3.el7启动docker
java
systemctl start docker查看docker版本
java
docker version查看docker 启动状态
java
systemctl status docker查看端口占用命令安装
java
yum install -y lsof安装Jenkins
创建Jenkins持久化目录
java
mkdir -p /root/docker/jenkins运行部署容器
java
docker run -d \
-u root \
--name forest_jenkins \
-p 9302:8080 \
-v /root/docker/jenkins:/var/jenkins_home \
-v /var/run/docker.sock:/var/run/docker.sock \
-v /usr/bin/docker:/usr/bin/docker \
jenkins/jenkins:lts-jdk11安装Rancher
创建Rancher挂载目录
java
mkdir -p /data/rancher_home/rancher
mkdir -p /data/rancher_home/auditlog部署Rancher
java
docker run -d --privileged --restart=unless-stopped -p 80:80 -p 443:443 \
-v /data/rancher_home/rancher:/var/lib/rancher \
-v /data/rancher_home/auditlog:/var/log/auditlog \
--name forest_rancher1 rancher/rancher:v2.5.7Docker镜像加速
配置阿里云镜像加速地址
为啥要配置?Rancher依赖组件多,不配置下载镜像慢容易出问题
阿里云入口地址 https://cr.console.aliyun.com/cn-chengdu/instances/mirrors
加速地址获取:镜像工具 --> 镜像加速器 --> CentOS
java
sudo mkdir -p /etc/docker
sudo tee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://ncw0ue59.mirror.aliyuncs.com"]
}
EOF
sudo systemctl daemon-reload
sudo systemctl restart dockerJenkins构建命令记录
Pre Steps
bash
echo "登录阿里云镜像"
docker login --username=957005099@qq.com registry-vpc.cn-chengdu.aliyuncs.com --password=lin1314..
echo "构建dcloud-common"
cd dcloud-common
mvn install
ls -alhPost Steps
其他微服务替换dcloud-后面的名称即可
镜像地址在阿里云容器查看
bash
ls -alh
cd dcloud-gateway
ls -alh
echo "网关服务构建开始"
mvn install -Dmaven.test.skip=true dockerfile:build
docker tag dcloud/dcloud-gateway:latest registry-vpc.cn-chengdu.aliyuncs.com/forest-dcloud-short-link/dcloud-gateway:v1.1
docker push registry-vpc.cn-chengdu.aliyuncs.com/forest-dcloud-short-link/dcloud-gateway:v1.1
mvn clean
echo "网关服务构建推送成功"
echo "=======构建脚本执行完毕====="Nginx-网关gateway的区别和微服务获取用户ip
Q: 容器部署微服务,内部如何获取用户访问来源IP呢?
A: 通过Nginx反向代理透传过去
nginx
upstream gateway {
server 112.74.107.230:80;
}
server {
listen 80;
server_name localhost;
location / {
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_pass http://gateway/;
}
}Q: 为啥有了gateway,还需要nginx呢?
Q: 前端请求到gateway,gateway在转发到相应的业务微服务,为什么不可以直接从nginx转发到相应的业务中心,还要加多一层
A: nginx和Spring Cloud Gateway在功能上是有一些重叠的地方,但是各司其职互相配合会更强大
Spring Cloud Gateway层
可以认为是业务网关,针对SpringCloud体系专⻔推出, 但是如果有其他服务不是用Cloud开发的怎么办?
有部分复杂业务逻辑nginx解决不了,可以用gateway用 java语言开发
容器部署微服务的ip地址一直在换,需要结合注册中心来 使用,所以gateway更灵活
Nginx
关注的是协议和路由的转发,聚合入口方便配置管理
在性能、容错机制上比Gateway强,多语言多环境下兼容 性更好
日志统计、协议路由转发、业务数据缓存前置、资源压缩等也是比较强大
配置HTTPS证书更灵活、Openresty+Lua开发各个强大的功能模块
Nginx 源码安装
新建目录/usr/local/software
官网下载:http://nginx.org/en/download.html,上传至/usr/local/software 目录,推荐版本:nginx-1.18.0.tar.gz
安装 nginx 依赖包
shell
yum -y install gcc zlib zlib-devel pcre-devel openssl openssl-devel解压 nginx
shell
tar -zxvf nginx-1.18.0.tar.gz编译安装
shell
#进入解压目录
cd /usr/local/software/nginx-1.18.0
./configure
make
make install默认安装路径:/usr/local/nginx,查看是否安装成功
nginx
/usr/local/nginx/sbin/nginx -V启动配置
shell
cd /usr/local/nginx/sbin
#启动
./nginxnginx
upstream gateway {
server 112.74.107.230:80;
}
server {
listen 80;
server_name localhost;
location / {
proxy_set_header Host $host;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
proxy_pass http://gateway/;
}
}shell
#重新加载配置文件
./nginx -s reload安装 SSL 依赖
bash
./configure --prefix=/usr/local/nginx --with-http_stub_status_module --with-http_ssl_module
make
make installNginx配置https证书
nginx
server {
listen 443 ssl;
server_name 16web.net;
ssl_certificate /usr/local/software/biz/key/4383407_16web.net.pem;
ssl_certificate_key /usr/local/software/biz/key/4383407_16web.net.key;
ssl_session_cache shared:SSL:1m;
ssl_session_timeout 5m;
ssl_ciphers HIGH:!aNULL:!MD5;
ssl_prefer_server_ciphers on;
location / {
root html;
index index.html index.htm;
}
}