Appearance
什么是架构师
英文 Architect 源于建筑学,在软件工程当中的架构师和建筑工程当中建筑师有很多共性,都是负责项目宏观的架构设计和整体把控;在软件工程领域中就是软件项目的总体设计师负责人
对于大部分程序员来说,架构师算是职业最终目标
互联网行业常⻅的架构师岗位
解决方案架构师:技术选型+难点攻克+沟通管理
为特定的解决方案提供一个一栈式的架构,深入理解该行业的商业模式,能够把握行业的市场和技术发展趋势,推动行业产品、解决方案和合作生态的落地
大数据架构师:技术选型+难点攻克+沟通管理
网络架构师:技术选型+难点攻克+沟通管理
应用架构师:技术选型+难点攻克+沟通管理
业务架构师:技术选型+难点攻克+沟通管理
系统架构师:技术选型+难点攻克+沟通管理
总结
虽然都是架构师【很多共性】但侧重不同, 在互联网公司里,多数架构师也充当技术 Leader 的⻆色
大公司才有很多架构师的细分,公司规模越小,架构师职责越多
架构师属于【全能型人才】
多数人的架构师成⻓方向-应用架构师
java架构师、go架构师、C++架构师 等
具体做的事情:产品PRD设计->架构师设计->方案评审->-开发->测试->上线->版本迭代更新
如何成为架构师
技术
技术解决项目业务的问题,通过业务驱动技术发展,技术反哺业务
业务起⻜是体现技术最大的价值,才能证明技术的真正价值
管理
沟通讲人话,你的业务方不指技术团队,还有产品、运营、客服团队很多
带团队、做好项目
对上汇报,对下管理
业务
识别重点+时间线
每个团队项目不少, 把握主链路
业务部⻔最需要的技术人员,口碑和技术最好的则这人的方式值得你去学习
架构师的技术广度和深度是怎样的
技术人员对技术要精还是要广,这个问题没有明确标准的答案
精于基础,广于工具,熟于业务,保持持续学习的心态
找到最适合自己的技术成⻓路径,持续学习
成⻓学习建议
学习做事方法,目标明确,推进项目落地,拿结果
沉下心来做事,最终的结果是水到渠成
不要给自己设限,学习的过程中要常去思考、总结复盘
遇到技术问题不慌乱,有自己标准的排查思路,解决后要能总结复盘
专业技能任然是立身之本,努力让自己超过同层级的技术能力,成为那20%
不要求整个架构100%掌握,掌握80%,可以理论上认为当下超过80%程序员
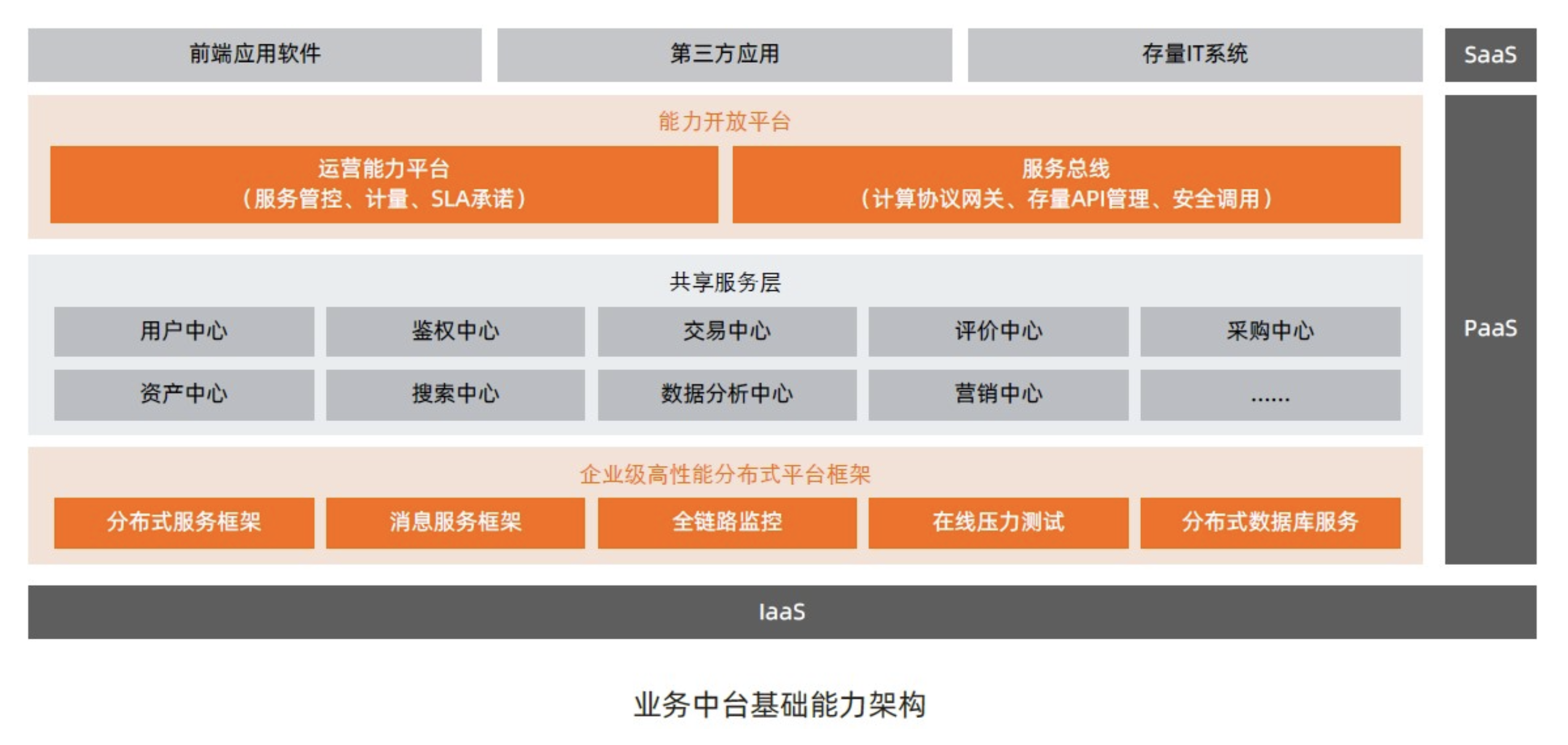
中台概念解释-系统复用
快速理解
不是单纯技术层面、系统层面,而是企业的组织架构,一种理念
接触过的中台概念
方法复用、类要复用、模块复用
系统复用 是更大层级上的复用,即中台
总结
中台就是以共享系统服务的形式存在,提炼各个业务域的共性需求,打造成组件化的系统
核心业务能力以服务的方式进行沉淀,实现服务在不同场景中的业务能力复用
以接口的形式提供给前台使用, 最大限度地减少系统建设中的“重复造轮子“的问题
比如:业务中台是加快系统研发上线,提高效率,但不是完全不用写任何代码,只是更少而已
分类
业务中台
业务微服务:商品中心、用户中心、支付中心、物流中心、营销中心等
技术中台
基础设施:基础服务、分布式缓存|队列|文件|调度
运维告警:监控中心、配置中心、DevOps平台
自动化平台:自动化测试平台
数据中台
数仓建设、用户画像、推荐系统、数据大屏...
AI中台
案例一(图片来源:阿里云数字政府|政府行业业务中台)
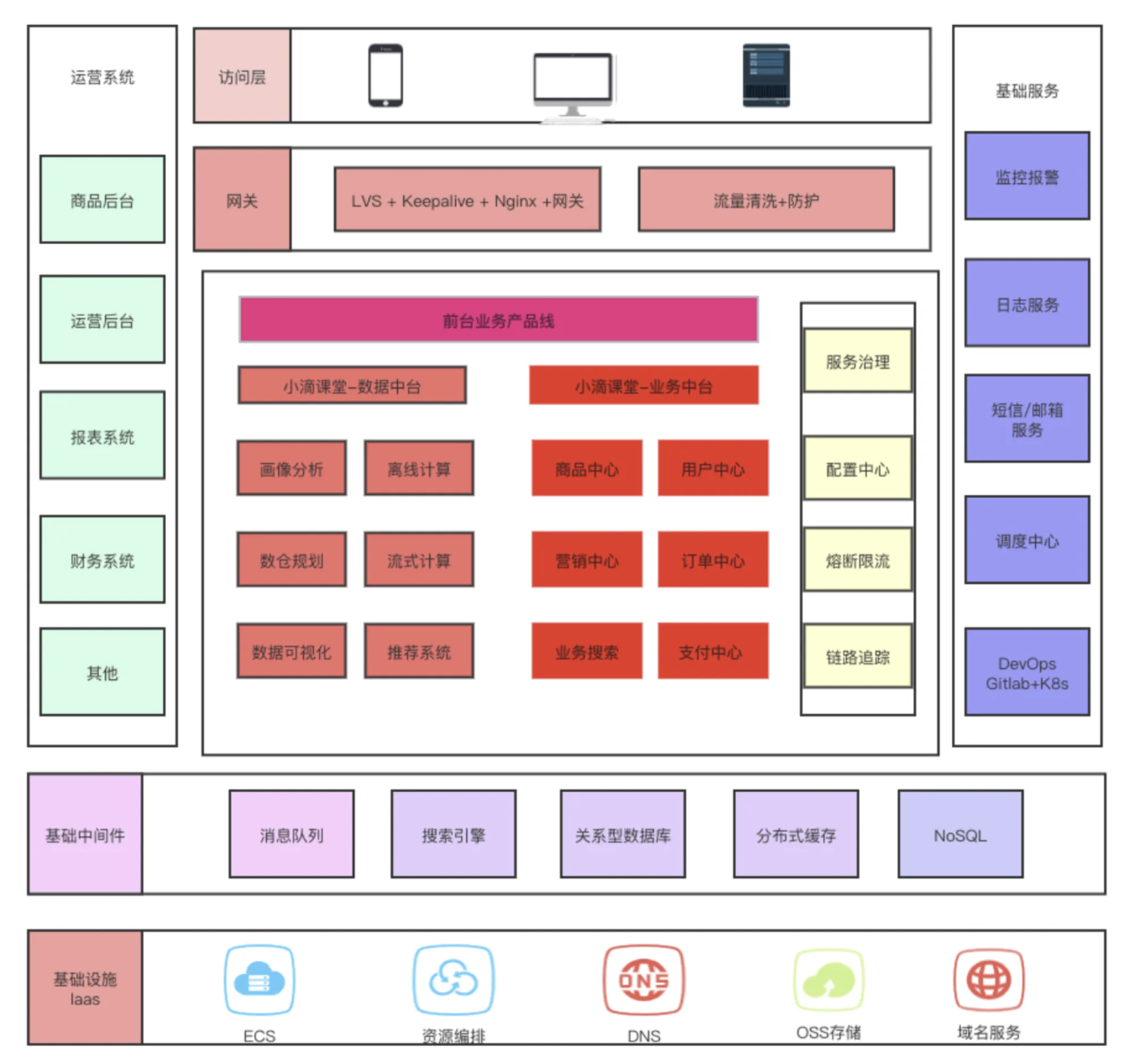
案例二:电商平台
是否要建设中台
企业IT生态系统庞大大
大量低水平重复建设的系统
各项业务数据互通
中台建设要求
要求对业务流程有一个【标准的抽象】,相关的业务能在这个标准流程里面进行
作为中台,需求肯定会很多,系统设计时要让系统可扩展性强
对系统设计抽象有比较强的品控,不要因为多人共建让系统代码迅速的腐化膨胀
突出关键能力 -【抽象能力】
顶层设计-锻炼架构师的业务抽象能力
注意
架构师的能力之一就是抽象能力
即做顶层设计,有多种方式,一种是自顶向下,另一种是自底向上
什么是抽象能力
百科解释:从具体事物抽出、概括出它们共同的方面、本质属性与关系等,而将个别的、非本质的方面、属性与关系舍弃,这种思维过程,称为抽象
说人话
发现不同事物之间的共同之处,异中求同,同类归并;
抽象的层次没有确定性的答案,核心就是满足业务场景的需要
抽象层次越高,细节越少,普适性越强,把握好边界问题,适度即可
原则
越顶层越抽象
下层独立上层的存在
高内聚,低耦合
代码案例
JDK代码:java集合、IO流量的顶层类
支付平台API设计
微信支付、支付宝支付、抖音支付、京东支付
实现代码前,列举下 需要抽象的API
下单
查询订单
关闭订单
支付结果通知
申请退款
查询退款状态
退款结果通知
账单查询 下载账单
架构师必备技术一图胜千言-架构图
如何画大饼-架构图
什么是架构图
架构图 = 架构 + 图
用图的形式把系统架构展示出来,配上简单的文案
画架构图是为了什么
一图胜千言,解决沟通障碍,给不同的【业务方】看懂
业务方很多,不同人看到⻆度不一样,你让【产品经理】看 【物理部署视图】他看得懂?
画架构图有哪些理论,有没最合适的架构图画法
架构图本质上是从不同的视⻆,不同的抽象⻆度去看,业界存在多个划分理论
那画架构图肯定有一定的【架构设计理论】主流的有多个 TOGAF、RUP 4+1 等
没有最合适的的架构图画法,只有最适合的
脱离实际业务场景的架构图,基本都是不合格的
如何判断架构图的好和坏?
业务抽象设计的合理性,是否满足高内聚、低耦合的要求,不能太宽泛,也不能太细粒度
层级划分目标系统边界,自下而上 或 由上而下,一般包括 基础设施、数据层、应用层、用户层四个层次
纵向分层:上层依赖于下层越底层,越是基础服务;横向并列关系,级别相同
理清架构图类型、业务要全面、专业术语一致、图形清晰美观、颜色类型划分合理
最重要是:你的业务方能满意+看懂!!!
不同架构图应该使用哪种方法来画?
可以用的表示法和工具很多,没有太多的限制,把握对应的视图关注点才是关键
Xmind、EdrawMax、PPT、PowerDesigner
OmniGraffle、Visio、Process On
开始阶段不要陷入过度设计中,没那么多需求不一定要那么多图(你是否有那么多客户)
关于UML
没有使用标准的架构描述语言,要注明架构图元素的用意(比如方框、形状、边框、线条、颜色等等)
使用标准的架构描述语言,只要在图例里添加关键性的架构描述,但是UML不太灵活
所以可以不用UML构图,但架构图的组成元素,要保证符合一贯理解
架构理论TOGAF和初识业务架构图
遵循架构设计理论
画架构图肯定有一定的【架构设计理论】主流的有多个 TOGAF、RUP 4+1 等
什么是【 TOGAF】
全称 The Open Group Architecture Framework 企业架构标准
给企业架构专业人士之间的沟通提供一致性保障,设计上注重灵活性,可用于不同的架构⻛格。
不同架构视图承载不同的架构设计决策,支持不同的目标和用途
业务架构:定义业务战略、企业治理、组织架构和关键业务流程。
是对业务需求的提炼和抽象,使用一套方法论对项目所涉及需求的业务进行业务边界划分
能比较清晰地看到系统的业务全貌,需求分析是否做到位,功能开发是否达到预期目标,都以此为依据
比如
开发一个电商网站,理清业务逻辑,比如订单、支付、用户、商品进行划分
不用考虑技术实现、并发量、部署架构等
业务架构图中尽量不出现技术的字眼,不同架构图的读者是不同的,确保能看懂。
无技术背景人员可参与实现的讨论,向技术人员描述解决方案核心要做什么,必须实现的关键是什么
也是【老板层面】比较关注的点,常规技术同学是到 应用/数据/技术架构这层比较多
秒懂-IaaS-PaaS-SaaS
三种云服务模型, 也称为三层架构
IaaS 基础设施即服务 Infrastructure as a service
虚拟的硬件资源,如虚拟的主机、存储、网络、安全等资源
最熟悉的例子:阿里云ECS主机的带宽、磁盘空间、GPU等
PaaS 平台即服务 platform as a service
为开发人员提供了一个框架,使他们可以基于它创建自定义应用程序
最熟悉的例子:阿里云OSS、RDB、短信服务、日志服务
SaaS 软件即服务 software as a service
云应用程序服务,利用互联网向其用户提供应用程序,这些应用程序由第三方供应商管理
公司产品:淘宝、小鹅通、亚⻢逊,CRM(客户关系管理)、HRM(人力资源管理)、SCM(供应链)
它们的区别
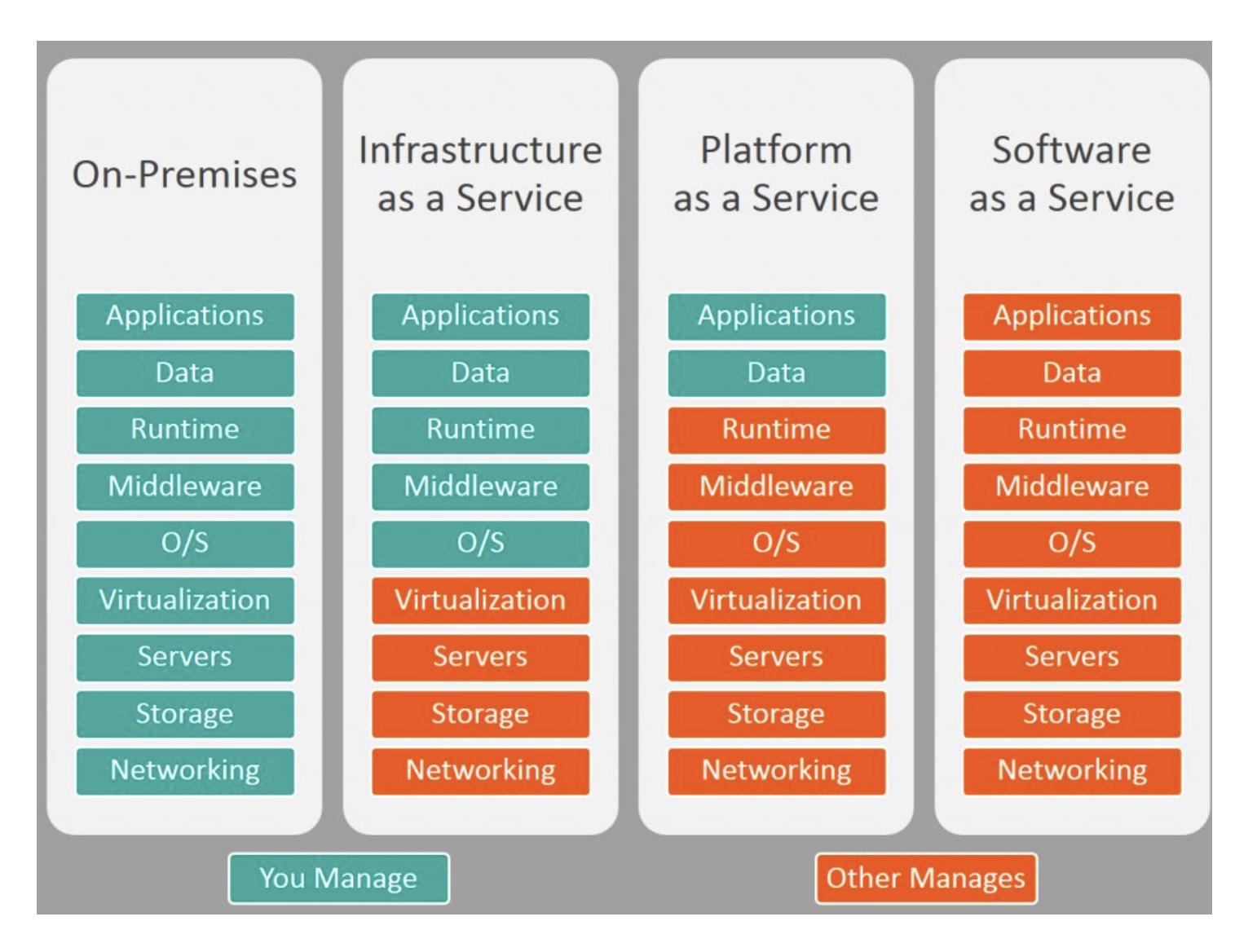
总结
从Iaas到SaaS的过程,企业的云化的程度也越来越高,内部IT所需要做的事越来越少。
可以这么看,运维同学经常打交道的是IaaS,开发经常打交道的是PaaS,运营和客户经常打交道的是 SaaS
当个画家-教你画高大上的业务架构图
在画架构图之前,想清楚3个问题,架构图想表达什么?有什么用?给谁看?
表达是业务系统之间的关系,梳理业务结构
将复杂的业务逻辑简单化,降低理解难度,更方便业务方理解
给业务方查看,业务相关干系人
画图三步走
分层
业务按照层级进行划分,各个层级属于独立的版块
下层为上层提供服务能力支撑
比如:laaS / PaaS / SaaS
分模块
同层级中进行小归类
属于平行关系,可以独立存在
比如:能力开放平台 有运营能力平台、服务总线
分功能
独立功能划分出来,即业务入口
业务方重点关注的功能点,可以认为是微服务划分
比如
能力开放平台:有运营能力平台 里面有 服务管控、SLA承诺、计量服务
当个画家-教你画高大上的应用架构图
什么是应用架构图
是对整个系统实现的总体架构 , 应用架构和系统架构很大类似
一方面承接业务架构的落地,一方面影响技术选型
注意:一般应用架构图【不加入太多技术框架和实现】
作用
根据业务场景 对系统进分层,指出开发的原则、系统各个层次的应用服务
指导软件的研发,包括不限于制定应用规范、定义接口和数据交互协议,满足功能性需求和非功能性需求
业务方
研发人员,各层级架构师,各层级技术管理者
分类
多系统应用架构,用来分层次说明不同系统间的业务逻辑关系、系统边界等,比如分布式、微服 务
单系统应用架构,用来分层次说明系统的组成模块和功能点之间的业务逻辑关系,比如单体应用
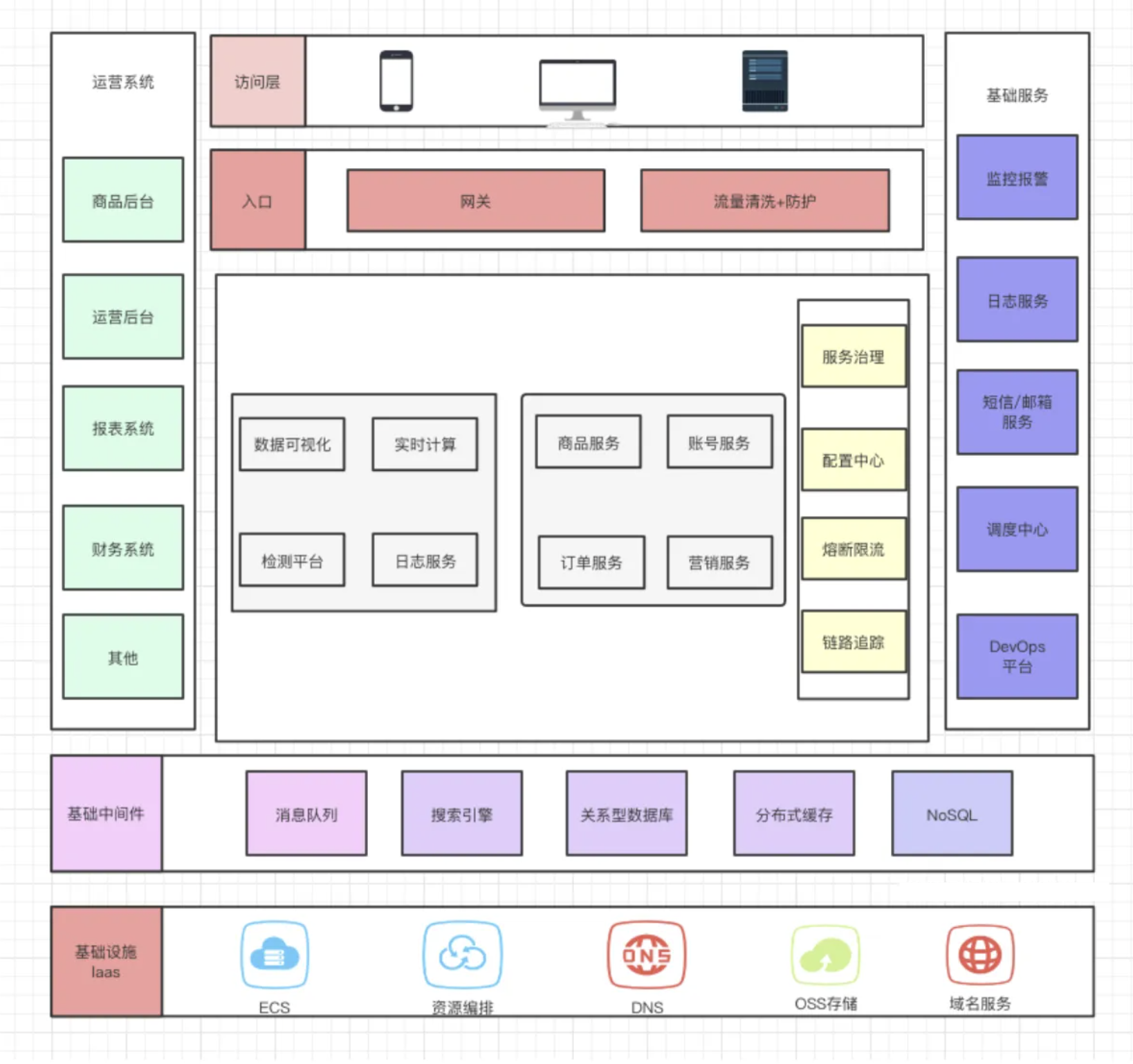
常规分层
表示-展现层:负责用户体验
业务-服务层:负责业务逻辑
数据-访问层:负责数据库存取
案例
细分领域-技术架构图和数据架构图
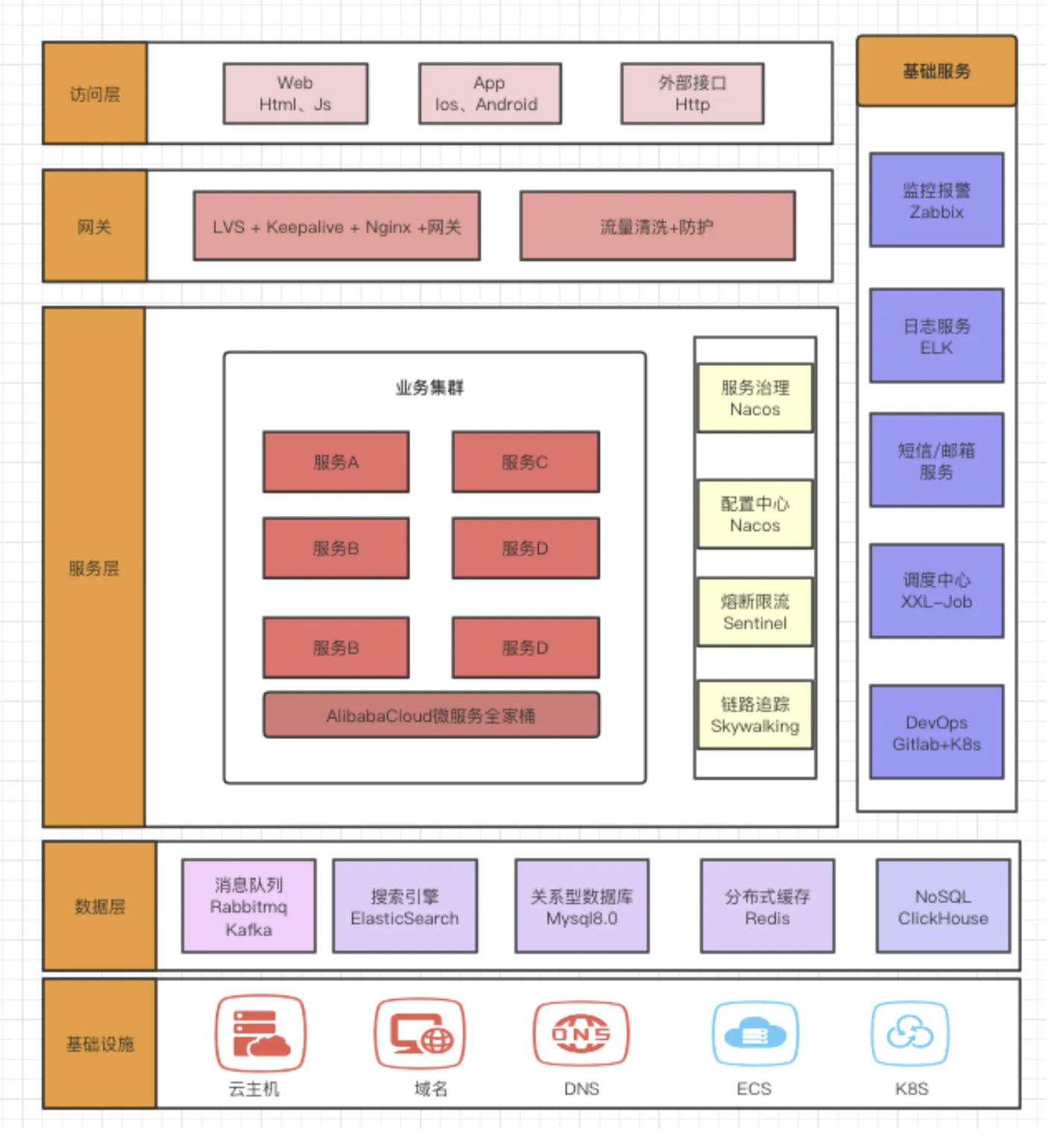
什么是技术架构
应用架构本身只关心需要哪些应用系统,不关心在整个项目中你需要使用哪些技术
技术架构则是实现应用架构的承接方,识别技术需求,进行技术选型,描述技术之间的关系
解决的问题包括
技术层面的分层、开发语言、框架的选择
通信技术、存储技术的选择、非功能性需求的技术选择等
案例
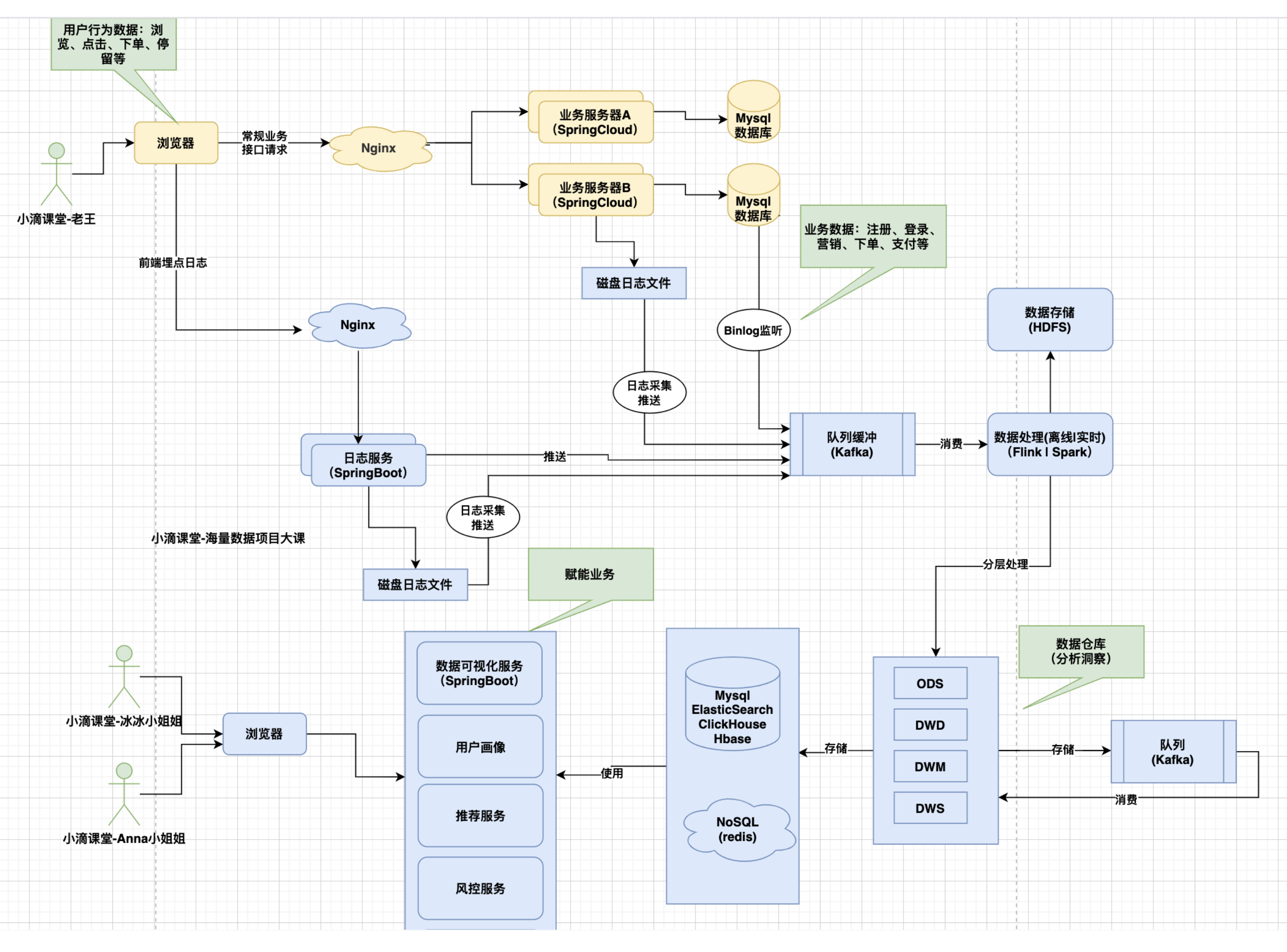
什么是数据架构
描述一个组织逻辑的和物理的数据资产和数据管理资源的结构
从数据视⻆,表达数据从产生到消费应用的全过程
比如做一个电商实时大屏,数据来源有哪些,经过哪些组件处理,最终存储和应用到哪里
常规里面不加具体的技术实现,但有时会方便沟通,则加入对应的技术实现
案例
业务-应用-技术-数据架构图总结回顾
重点:业务架构是战略,应用架构是战术,技术和数据架构是装备
业务架构
表达业务是如何开展的,服务于业务目标,通过描绘业务上下层关系,简单的业务视图降低业务系统的复杂
应用架构
是对整个系统实现的总体架构,应用架构和系统架构很大类似
一方面承接业务架构的落地,一方面影响技术选型
注意:一般应用架构图【不加入太多技术框架和实现】
技术架构
应用架构本身只关心需要哪些应用系统,不关心在整个项目中你需要使用哪些技术
技术架构则是实现应用架构的承接方,识别技术需求,进行技术选型,描述技术之间的关系
解决的问题包括
技术层面的分层、开发语言、框架的选择
通信技术、存储技术的选择、非功能性需求的技术选择等
数据架构
描述一个组织逻辑的和物理的数据资产和数据管理资源的结构
从数据视⻆,表达数据从产生到消费应用的全过程
方法
架构图想表达什么?有什么用?给谁看?
画图三步走:分层、分模块、分功能
如何判断架构图的好和坏?
业务抽象设计的合理性,是否满足高内聚、低耦合的要求,不能太宽泛,也不能太细粒度
层级划分目标系统边界,自下而上 或 由上而下,一般包括 基础设施、数据层、应用层、用户层四个层次
纵向分层 上层依赖于下层越底层,越是基础服务;横向并列关系,级别相同
理清架构图类型、业务要全面、专业术语一致、图形清晰美观、颜色类型划分合理
重要是:你的业务方能满意+看懂!!!
类图
依赖关系
尖括号 + 虚线表示
当一个对象依赖另一个对象提供的服务时,就是依赖关系
继承泛化关系
三⻆ + 实线表示
泛化关系为 is-a 的关系,xx是一个yy的子类
实现关系
三⻆ + 虚线表示
开发里面的类 实现 接口
关联关系
尖括号 + 实线 表示
一个类中的 对象与对象 之间的引用关系,类中的 成员变量
组合关系
实心棱形 + 实线表示
属于强关联关系,由整体指向部分
聚合关系
空心棱形 + 实线表示
弱关联关系 ,由整体指向部分
如何上手公司项目
切记:不要直接看代码
看产品
看产品需求文档
看项目技术栈
看项目技术架构图和部署环境
看数据库ER设计和关联关系、是否有分库分表
看团队负责的功能、模块、服务、包作用
调下团队负责的某个功能链路
按照上述步骤看其他模块
如何衡量一个系统的架构设计目标
当下互联网项目面临的【核心大挑战】
业务发展需求变动快
高并发大流量
海量数据
可用性
网络+重点环境复杂
业务安全
架构目标
业务需求⻆度
高效+优质的解决当下业务需求问题
非业务需求⻆度
高性能: 请求延迟Latency再多少ms以内
高可用: SLA达到几个9
高并发: 每秒 TPS 几万
易扩展: 业务变动易调整,合理业务逻辑抽象,事件驱动架构和分布式服务
可伸缩: 快速水平伸缩,秒级扩容
安全性: 业务数据安全保证
总结
系统并非一蹴而就,架构目标也是随着变化,业务推送技术发展,技术反哺业务
系统和业务的演进,没有最好的架构,只有最适合的架构
任何一个解决方案、架构方案提出都要说下优缺点,逼迫自己思考
对业务有很好的了解,快速高效的用户的痛点
把简单的东⻄想复杂,控制好⻛险和准备好未来
把复杂的东⻄做简单,做好产品且控制好成本
最后把复杂的东⻄讲简单,做好传承
如何找问题点
先有识别问题能力,再学解决问题能力
内部因素
水管效应:最细的水管是流量瓶颈
木桶效应:最低的木桶是容量的上限,当然可以倾斜
常规四大件(哪些操作消耗四大件)
CPU:序列化、大量线程、大量计算
内存:大量对象产生/缓存使用/连接占据
带宽:大文件操作、突发流量
磁盘IO:大量文件IO、不合理日志、高频数据库操作
案例
大促前批量服务扩容,每个服务占据了数据库连接,导致底层数据库连接不够
双11修改下单地址失败,其他服务性能很好,但是这个导致了问题,从而链路奔溃
外部因素(三方服务)
支付平台
支付中心,微信支付统一下单每秒600- QPS, 多账号策略,采用负载均衡方式进行操作
云产品: CDN/存储/计算能力
节点网络覆盖度 / 产品本身的硬件资源问题
比如 视频CDN节点覆盖
互联网系统架构-三高下的架构设计
高并发
TPS
Transactions Per Second 每秒事务数,可以是一个接口、多个接口、一个业务流程, 包括增删改操作
QPS
Queries Per Second,每秒查询数,指一台服务器每秒能够响应的查询次数
QPS 只是一个简单查询的统计,不能描述增删改等操作
如果只是查询操作 TPS = QPS
高可用
SLA 衡量一个系统可用性有多高,目标系统 7 x 24 小时不间断服务,云厂商在宣传自己产品SLA时多少个9
分类
时间维度
系统可以正常使用时间与总时间之比(全年为例子)1年 = 365天 = 8760小时
99.9 = 8760 0.1% = 8760 0.001 = 8.76小时
99.99 = 8760 0.0001 = 0.876小时 = 0.87660 = 52.6分钟
99.999 = 8760 0.00001 = 0.0876小时 = 0.087660 = 5.26分钟
请求次数维度
请求总次数和失败的占比 ( 1000次请求为例子,相对简单 )
系统可用性99%: 表示1000个请求中允许1000 * (1-99%) = 10个请求出错
系统可用性99.9%: 表示1000个请求中允许1000 * (1-99.9%) = 1个请求出错。
9越多代表全年服务可用时间越⻓服务更可靠,停机时间越短
但往往存在网络/机房问题,应用更新发版导致服务不可用
大厂多数业务4个9是刚需,5个9是目标,6个9是理想
高性能
RT来衡量系统的响应速度,程序处理速度非常快延迟低Latency,所占内存少,cpu占用率低
比如系统处理一个 HTTP 请求需要 100ms,这 100ms 就是系统的响应时间
三高不是孤立的,而是相互支撑的影响的
高并发方面要求Throughput 大于 10万
高性能方面要求请求延迟Latency小于 100 ms
高可用方面要求系统可用性 SLA高于 99.99%
但随着并发量上来,请求延迟肯定增大,处理不过来则可用性就会下降
高并发+高性能技术方案
多大并发才算高并发?
需要结合具体的场景和资源投入
1万QPS的商品列表查看不属于高并发,稍微结合缓存即可
5千TPS的下单接口属于高并发,链路不一样
系统架构
无状态业务-水平扩展(Scale Out),只要增加服务器数量,就能线性扩充系统性能
架构的难点是难做到全链路的水平扩展
[负载均衡]思想
节点轮询、随机、加权轮询、节点固定hash
应用场景
网络 DNS解析轮询
网关分发请求后端服务
应用服务内部RPC负载均衡
数据存储-分库分表-负载分发
[缓存]思想
本地缓存/分布式缓存
应用场景
前端浏览器缓存静态资源
网络DNS解析缓存
应用程序 内存缓存/分布式缓存
数据存储Mysql Query Cache
[池化复用]思想
线程池/对象池/连接池/内存池
应用场景
java线程池技术
Jdbc/Redis/HttpClient连接池
SpringIOC容器对象池
[异步]思想
多线程/消息队列
应用场景
前端ajax异步请求
RocketMQ/Kafka 同步双写-异步刷盘
应用程序多线程异步处理
[预处理-惰性更新]思想
定时任务/懒加载
应用场景
运营后台报表数据,定时任务提前计算好
Mybatis懒加载
[分而治之]思想
Mater-worker
应用场景
Hadoop中的MapReduce
JDK. Fork/Join Framework
消息队列的广播消息
归并排序算法
高可用技术方案
冗余集群化 + 自动故障转移failover
集群架构
将多个相同的应用程序集中起来提供同一种服务,某个节点故障不影响系统
可以横向扩展性增加节点提高并发处理能力
实际应用
微服务集群
Redis集群/Kafka集群/Nginx集群
Nacos集群/Mysql集群/ZK集群
熔断降级
保险丝,熔断服务,为了防止整个系统故障,抛弃一些非核心的接口和数据,返回兜底数据
限流
当访问频率或者并发请求超过其承受范围的时候,考虑限流来保证接口的可用性
漏斗模型,不管流量多大均匀的流入容器,令牌桶算法,漏桶算法
隔离
服务和资源互相隔离,比如网络资源,机器资源,线程资源等,不会因为某个服务的资源不足而抢占其他服务的资源
多活架构
同城双活-双机房
两个机房部署在同城,物理距离较近,两个机房用「专线」网络连接,比单个机房内延迟要大一些,但整体的延迟是可以接受的
异地多活-两地三中心
两地是指 2 个城市,三中心是指有 3 个机房,其中 2 个机房在同一个城市
同时提供服务,第 3 个机房部署在异地,只做数据灾备
操作系统的缓存
Buffer和Cache
Buffer 是对磁盘数据的缓存, Cache 是文件数据的缓存,两者既会用在读请求,也会用在写请求,只不过是多和少区别
缓冲(buffer)是用来加速数据"写入"硬盘,保存即将要写入到磁盘上的数据
缓存(cache)是保存从磁盘上读出的数据,用来加速数据从硬盘中"读取"
Cache 和 Buffer 的是为了解决 高速设备和低速设备之间的问题而设计的中间层,通过“流量整形”提高系统性能
Cache 将低速设备中常被访问的数据缓存起来
当高速设备需要再次访问这些数据时,命中 Cache 中的数据,以减少对低速设备的访问
Buffer 用于缓冲高速设备把数据写到低速设备时带来的压力
当数据量比较大时,Buffer能将数据分割成合适的大小,分批回写到磁盘
当数据量比较小的时候,Buffer 能将分散的写操作集中进行,减少磁盘碎片和硬盘的反复寻道
磁盘和IO
为啥IO读写性能差别那么大
dd 命令实践
dd: 用指定大小的块 拷⻉一个文件,并在拷⻉的同时进行指定的转换,下面是参数
if = 文件名: 输入文件名,缺省为标准输入,即指定源文件。< if = input file >
of = 文件名: 输出文件名,缺省为标准输出,即指定目的文件。 < of = output file >
bs = bytes: 同时设置读入/输出的块大小为bytes个字节, 可代替 ibs 和 obs
count = blocks: 仅拷⻉blocks个块,块大小等于指定的字节数
bs是每次读或写的大小,即一个块的大小,count是读写块的数
shell
#操作一
# 释放所有缓存
echo 3 > /proc/sys/vm/drop_caches
dd if=/dev/zero of=xdclass_testio1 bs=1M count=1024
#操作二
echo 3 > /proc/sys/vm/drop_caches
dd if=/dev/zero of=xdclass_testio2 bs=1M count=1024 oflag=direct
#操作三
echo 3 > /proc/sys/vm/drop_caches
dd if=/dev/zero of=xdclass_testio3 bs=1M count=1024 oflag=sync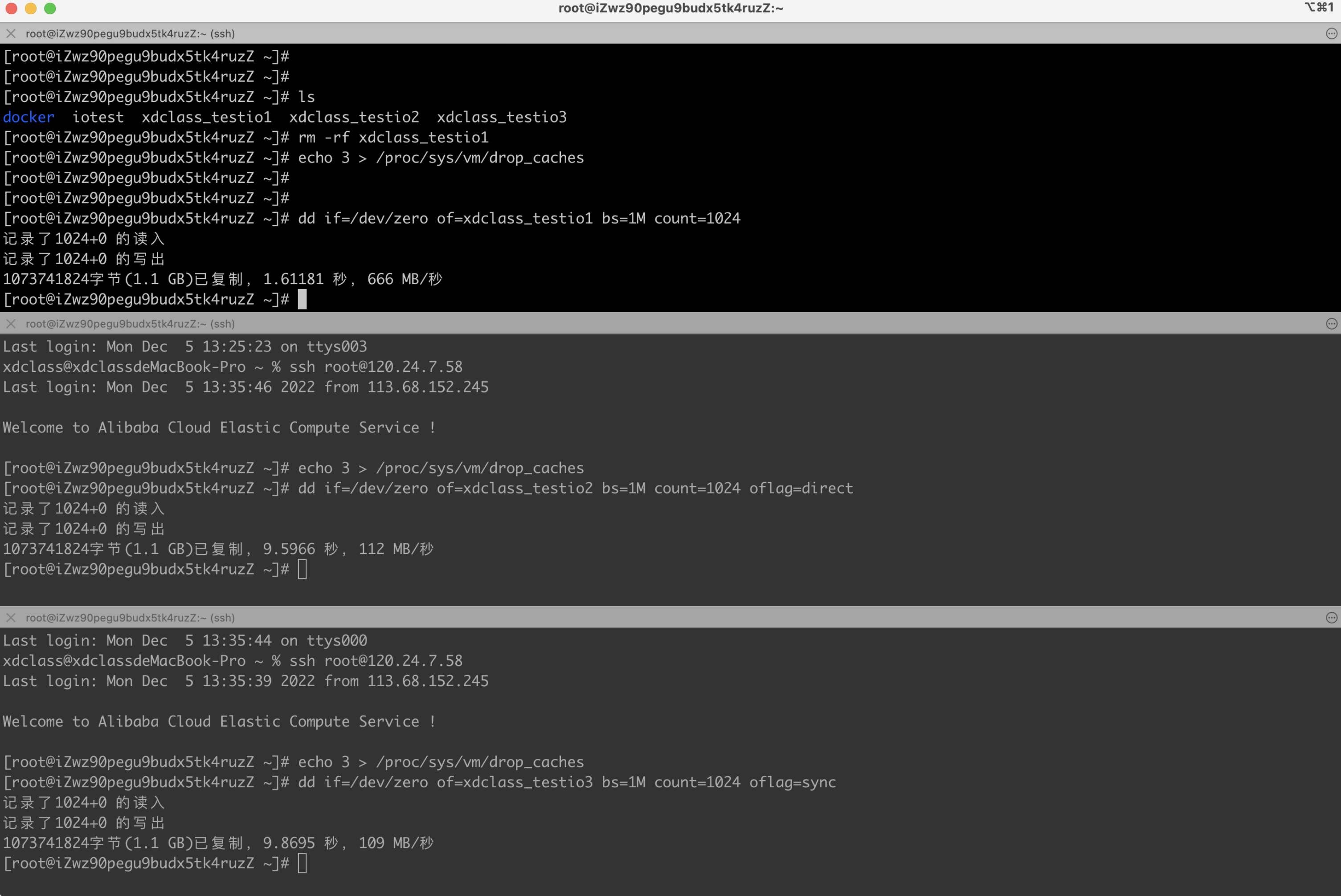
结果
有oflag的时候,文件复制速度是 oflag=direct 的多倍
原因:默认是buffered I/O,数据写到缓存层便返回,所以速度最快
oflag=direct的速度又比 oflag=sync 快了点
原因:数据写到磁盘缓存便返回,所以速度比上面的buffered I/O方式要慢
oflag=sync 的速度最慢
原因:写入的数据全部落盘才返回,所以速度比上面的仅写到磁盘缓存要慢
物理磁盘也会带有缓存 disk cache,用于提供I/O速度, 一般磁盘中带有电容,断电也能把缓存数据刷写到磁盘中
操作系统IO和虚拟文件系统VFS
什么是操作系统IO
输入(Input)和输出(Output),或者读(Read)和写(Write)
I/O模式可以划分为本地IO模型(内存、磁盘)和网络IO模型
I/O关联到用户空间和内核空间的转换。也称为用户缓冲区和内核缓冲区
用户态的应用程序不能直接操作内核空间,需要将数据从内核空间拷⻉到用户空间才能使用
read和write操作,都只能在内核空间里执行
磁盘IO和网络IO请求都是先放在内核空间,然后加载到内存的数据
什么是文件系统
在 Linux 中一切皆文件,文件系统是管理磁盘上的全部文件,文件管理组织方式多种多样,所以文件系统存在多样化
Q: 系统把文件持久化存储在磁盘上,那很多文件怎么管理和使用呢?
这个就是文件系统的职责,实现文件数据的查询和存储
文件系统是管理数据,而存储数据的物理设备有硬盘、U 盘、SD 卡、网络存储设备等
不同的存储设备其物理结构不同,不同的物理结构就需要不同的文件系统去管理
例子
Windows有FAT12、FAT16、FAT32、NTFS、exFAT等文件系统
Linux有Ext2、Ext3、Ext4、tmpfs、NFS等文件系统
查询系统用了哪些的文件系统 df -h -T

两个核心概念
索引节点(index node)
简称inode ,记录文件的元信息,比如文件大小、访问权限、修改日期、数据存储位置等
索引节点也需要持久化存储,占用磁盘空间。
目录项(directory entry)
简称为 dentry,记录目录结构,比如文件的名字、索引节点指和其他目录项的关联关系等,树状结构居多
存储在内存中,也叫目录项缓存。
虚拟文件系统VFS(virtual File System)
Q: 操作系统上有那么多的文件系统和物理存储介质,应用程序怎么编写使用呢?
虚拟文件系统就是做这个,调用读写位于不同物理介质上的不同文件系统, 为各类文件系统提 供统一的接口进行交互
在应用程序和具体的文件系统之间引入了一个抽象层,开发者不用关心底层的存储介质和文 件系统类型就可以使用
Linux的IO存储栈简略图
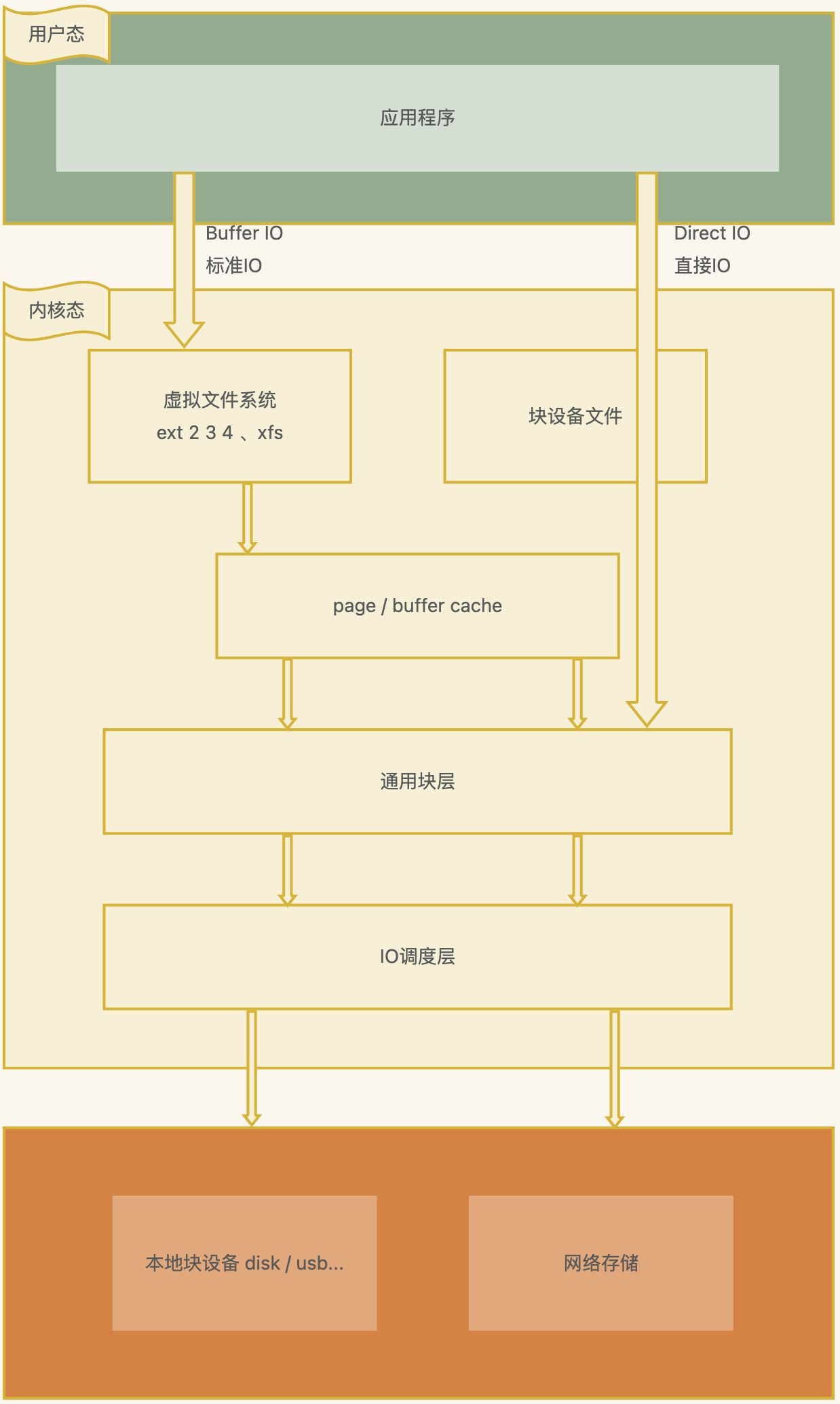
平时调用 write 的时候,数据是从应用写入到了C标准库的IO Buffer(存在用户态)
在关闭流之前flush下文件,通过flush将数据主动写入到内核的Page Cache中,应用挂了,数据也安全(存在内核态)
将内核中的Page Cache中的数据写入到磁盘(缓存)中,系统挂了,数据也安全,需要调用 fsync(存在持久化介质)
总结
操作系统的多级缓存和数据的可用性
操作系统也是程序,人家程序员也要考虑高性能
高性能: 多线程异步、多级缓存
对比日常开发的java微服务项目
多线程异步操作,响应快
微服务里面的多级缓存 ,guava本地缓存和redis分布式缓存
CPU内核态和用户态切换
用户态切换和内核态切换就是上下文切换
相当于不同权限访问级别,比如:应用程序只能操作有限的权限,而操作系统可以操作更底层的权限
CPU向磁盘写数据,要先经过buffer缓冲区,然后把缓冲区的数据分批写入磁盘中
固态硬盘和标记整理回收
固态磁盘SSD
固态电子元器件组成,没有盘片、磁臂等机械部件,不需要磁道寻址,靠电容存储数据
某块区域存在数据,机械硬盘写入可以直接覆盖;而固态硬盘需要先擦出,再写入
block块 擦的越多寿命就越短,业务数据高频更新,则不太建议使用固态硬盘
最小读写单位是⻚,通常大小是 4KB、8KB
性能高,IOPS可以达到几万以上;价格比机械硬盘贵,寿命较短
组成结构
SSD 多个裸片组成
裸片 多个平面组
平面 plane(多个blcok组成)
块 block(通常64个page组成一个block)
⻚ page 4k
磁盘的擦除数据
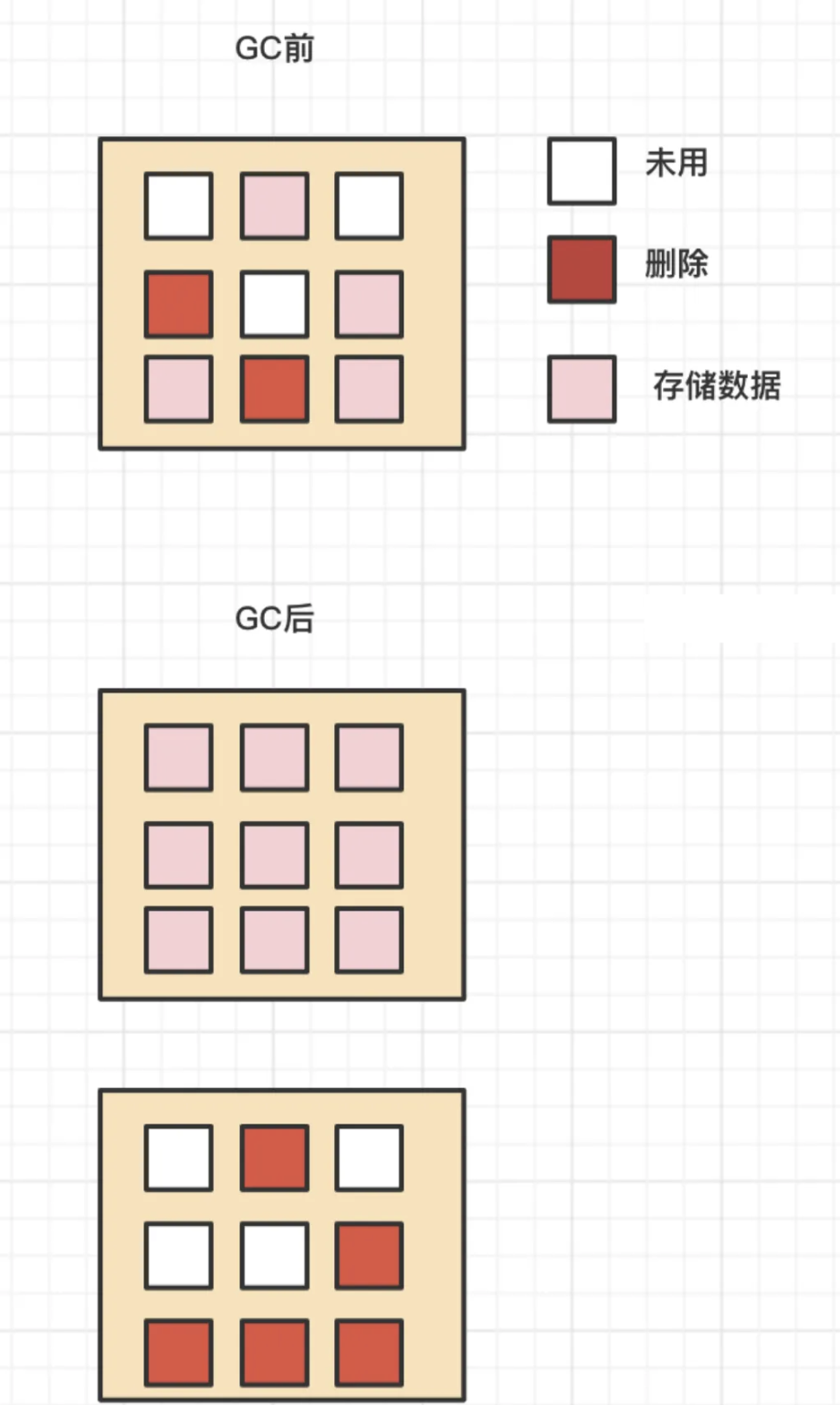
SSD里面最小读写单位是page,但是最小擦除单位是block
一个块上的某些⻚的数据被标记删除,不能直接擦除这些的⻚,除非整个块上的⻚都被标记删除
块还有其它有效数据,当有新数据只能写入白色区域,并不能利用红色区域,时间越⻓,不能被使用的碎片越多
解决方案 GC(Garbagecollection)垃圾回收
有一套标记整理机制程序,"有效"⻚数据复制到一个"空白"块里,然后把这个块完全擦除
那些被移动出数据的块上面的⻚要么没数据,要么是标记删除的数据,直接对这个块进行擦除
擦除数据类似JVM的GC,标记整理 Mark Compact
先对对象进行一个标记,看看哪些对象是垃圾
整理会在清除的过程中,把可用的对象向前移动,让内存更为紧凑,避免内存碎片的产生
整理之后发现内存更紧凑,连续的空间更多,就不会造成内存碎片的问题
业务选择(没有绝对,公司有钱另说)
业务大量写日志系统,时间滚动会定期清除老旧的日志,日志一般读的少
大量擦出会导致SSD寿命变短,所以不适合存放在SSD硬盘上,应该用HDD硬盘
操作系统的IO技术底层机制和应用
CPU的外包小弟DMA技术
DMA (Direct Memory Access)
直接内存访问,直接内存访问是计算机科学中的一种内存访问技术
DMA之前: 要把外设的数据读入内存或把内存的数据传送到外设,一般都要通过 CPU控制完成,利用中断技术
允许某些硬件系统能够独立于 CPU 直接读写操作系统的内存,不需中央处理器(CPU)介入处理
数据传输操作在一个 DMA 控制器(DMAC)的控制下进行,在传输过程中 CPU 可以继续进行其它的工作
在大部分时间CPU和 I/O 操作都处于并行状态,系统的效率更高
应用程序的读写数据
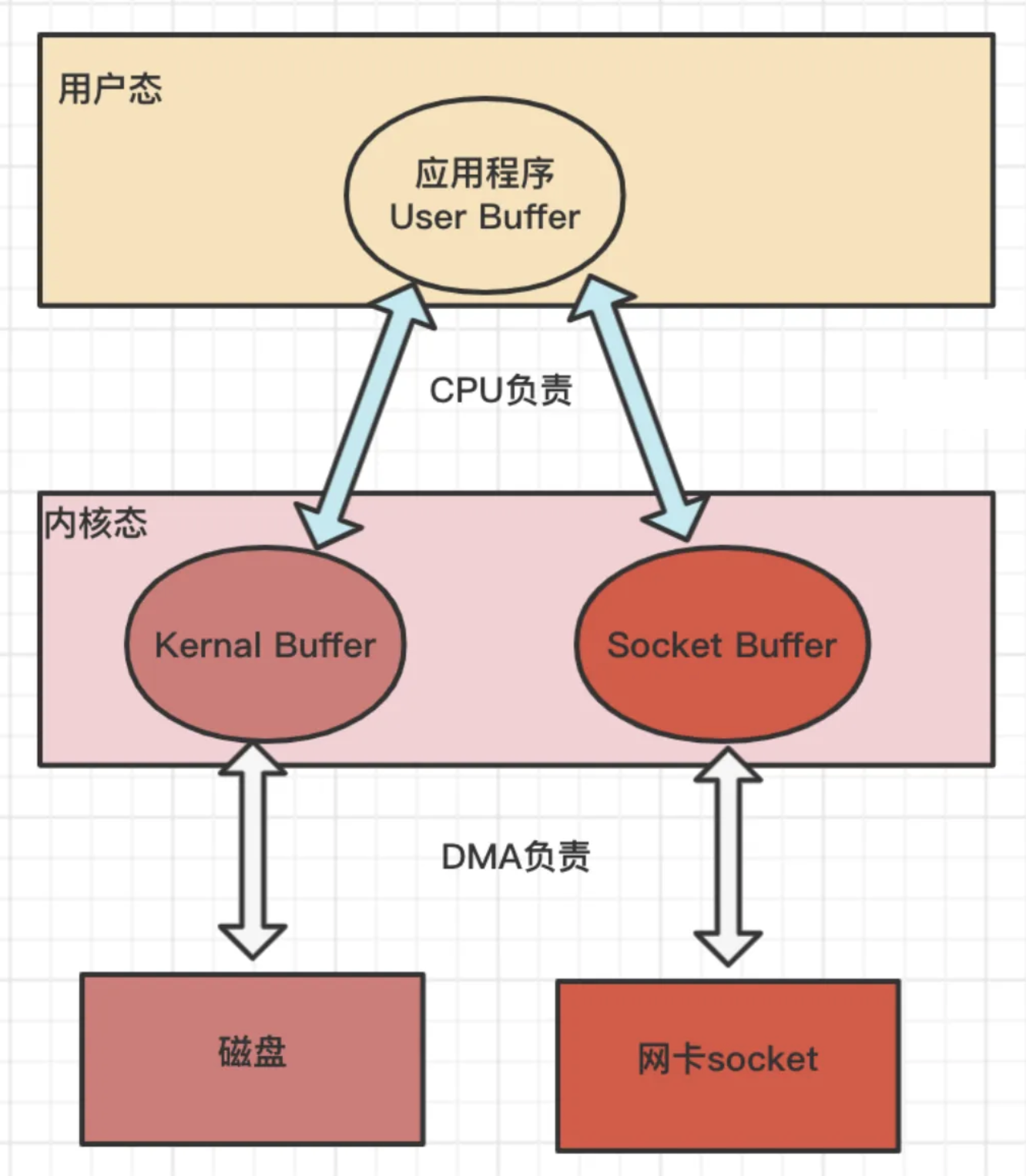
DMA的工作总结
(读)从磁盘的缓冲区到内核缓冲区的拷⻉工作
(读)从网卡设备到内核的soket buffer的拷⻉工作
(写)从内核缓冲区到磁盘缓冲区的拷⻉工作
(写)从内核的soket buffer到网卡设备的拷⻉工作
但是: 内核缓冲区到用户缓冲区之间的拷⻉工作仍然由CPU负责
DMA技术里面的损耗
CPU的用户态和内核态切换
CPU的内存拷⻉损耗
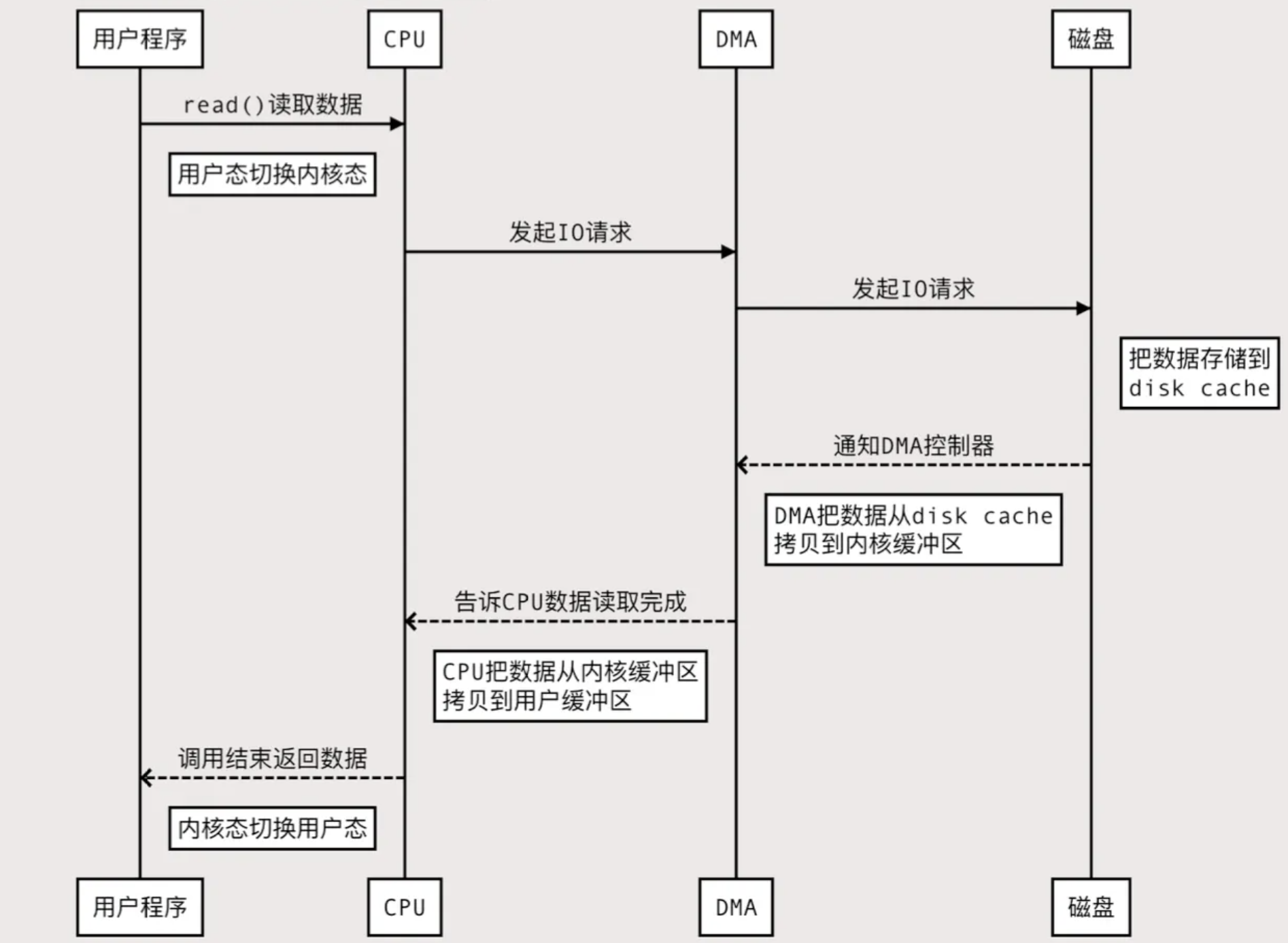
下图应用程序从磁盘读取数据发送到网络上的损耗,程序需要两个命令。先read读取,再write写出
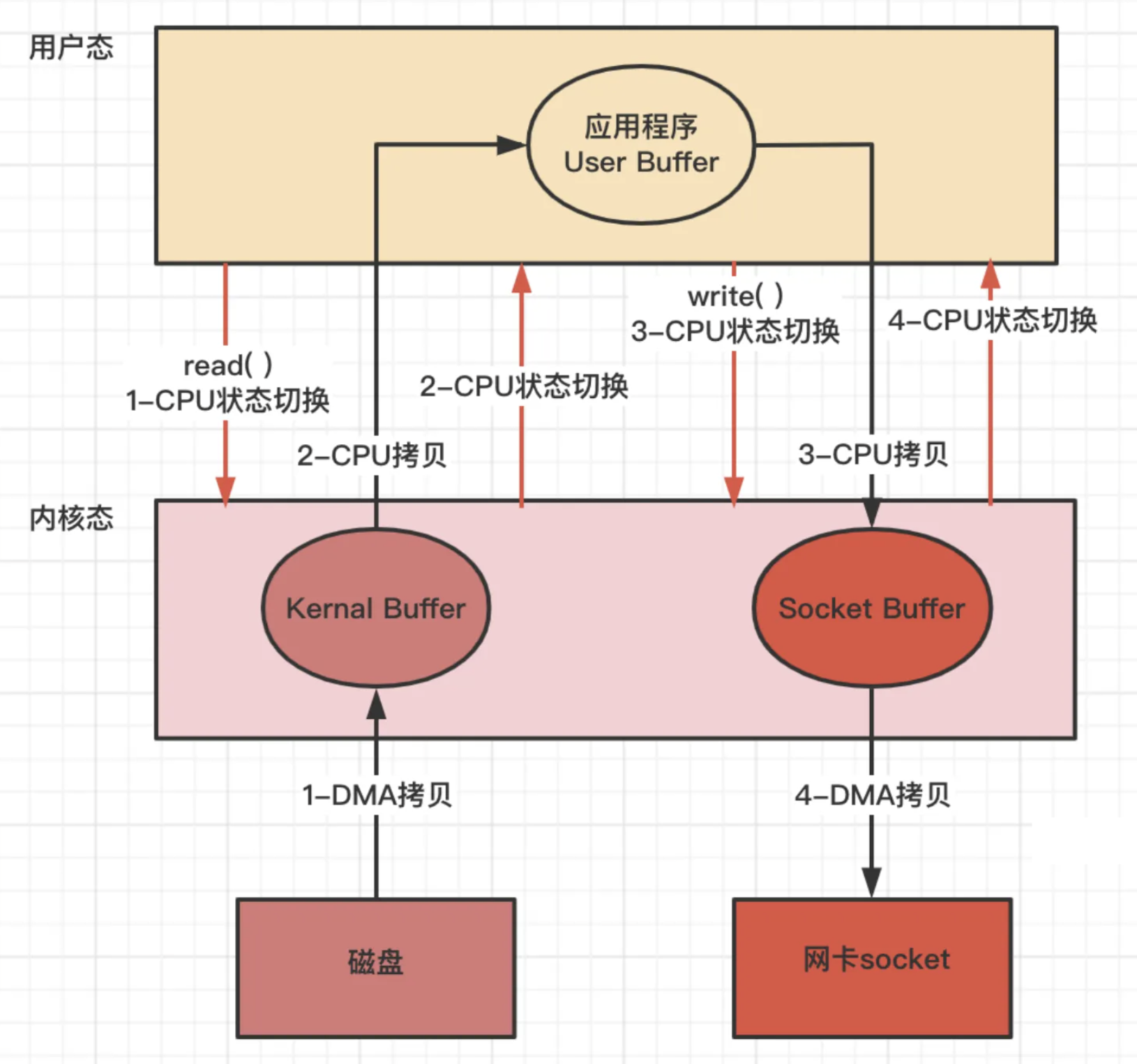
四次内核态和用户态的切换
四次缓冲区的拷⻉
读取: 磁盘缓冲区到内核缓冲区(DMA)
读取: 内核缓冲区到用户缓冲区(CPU)
写出: 用户缓冲区到内核缓冲区Socket Buffer(CPU)
写出: 内核缓冲区的Socket Buffer到网卡设备(DMA)
性能损耗操作
2次DMA拷⻉、2次CPU拷⻉、4次内核态用户态切换
计算机大神们怎么会容忍这类浪费呢,所以就诞生了零拷⻉
什么是零拷⻉ZeroCopy
只需要拷⻉2\3次 和 2\4的内核态和用户态的切换即可
ZeroCopy技术实现有两种(内核态和用户态切换次数不一样)
方式一 mmap + write
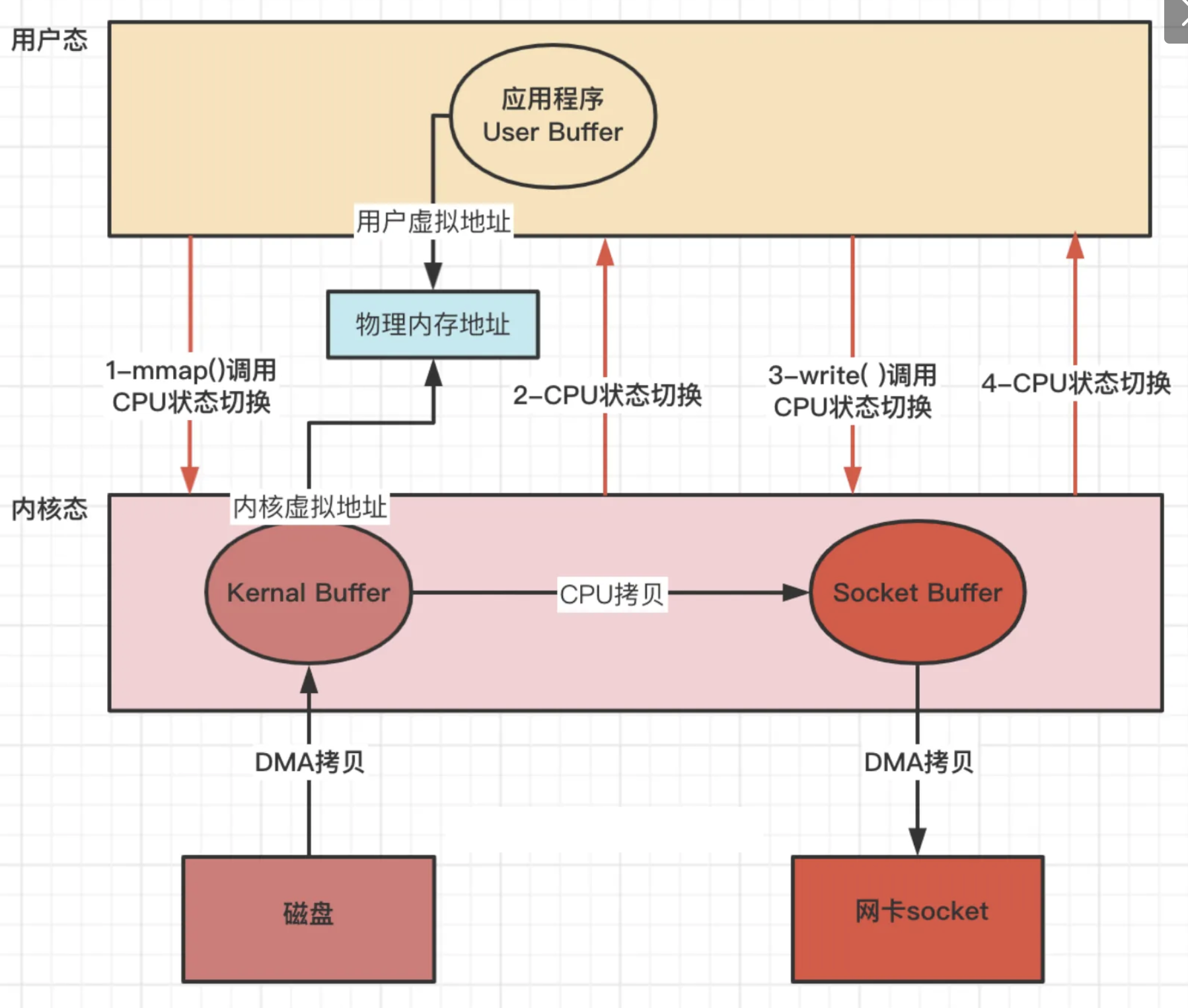
虚拟地址 通过多级⻚表 映射物理地址
2次DMA拷⻉、1次CPU拷⻉、4次内核态用户态切换
方式二 sendfile
Linux kernal 2.1新增发送文件的系统调用函数 sendfile( )
替代 read() 和 write() 两个系统调用,减少一次系统调用,即减少 2 次CPU上下文切换的开销
调用sendfile( ),从磁盘读取到内核缓冲区,然后直接把内核缓冲区的数据拷⻉到 socket buffer缓冲区 里
再把内核缓冲区的Socket Buffer给直接拷⻉给Socket协议栈 即网卡设备中)(DMA负责)
Sendfile( )
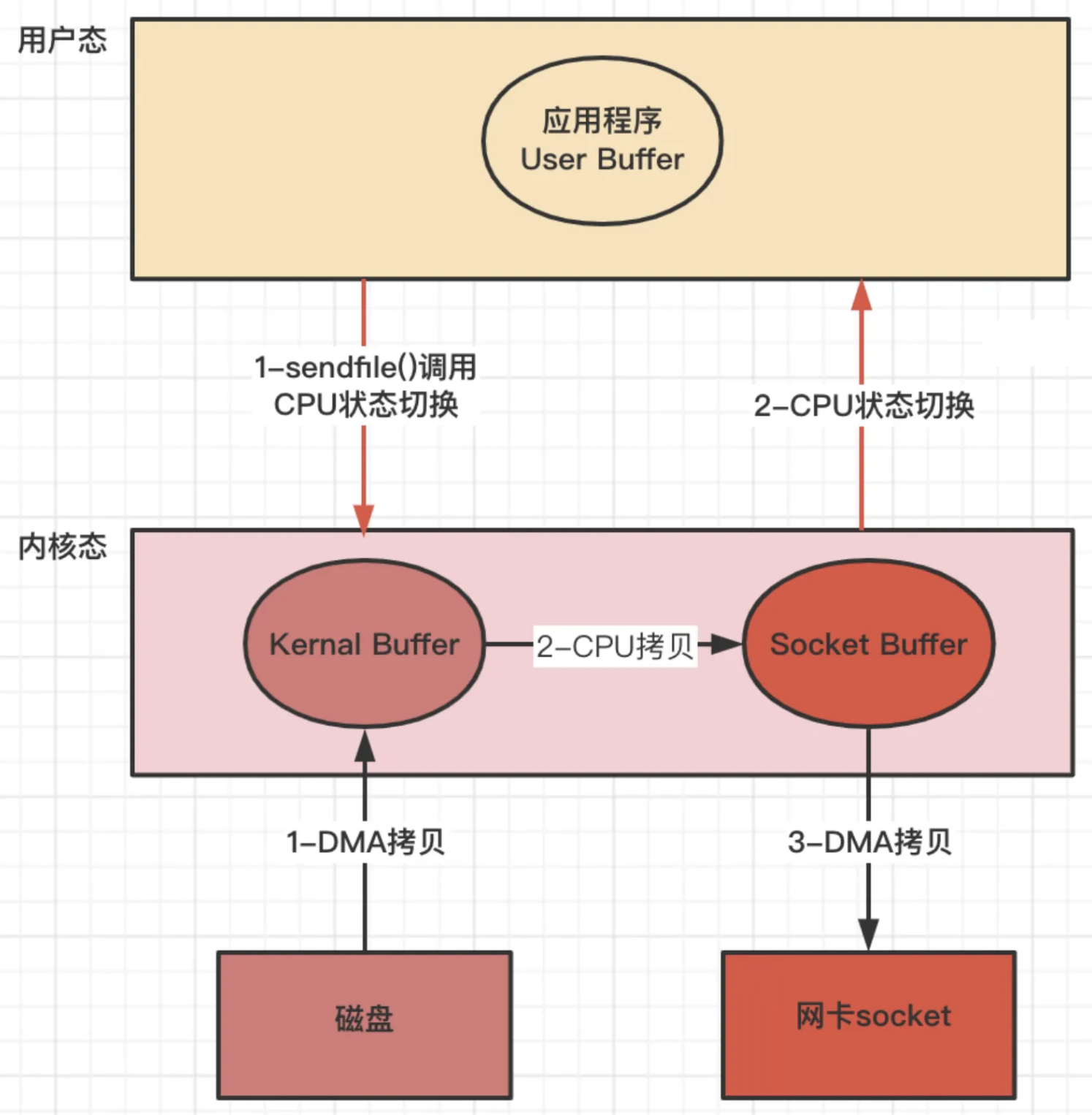
步骤
应用程序先调用sendfile()方法,将数据从磁盘拷⻉到内核缓冲区(DMA负责)
然后把 内核缓冲区的数据直接拷⻉到内核socket buffer(CPU负责)
然后把内核缓冲区的Socket Buffer给直接拷⻉给Socket协议栈 即网卡设备中,返回结束(DMA负 责)
损耗
2次DMA拷⻉、1次cpu拷⻉、2次内核态用户态切换
Linux 2.4+ 版本之后改进sendfile, 利用DMA Gather(带有收集功能的DMA),变成了真正的零拷⻉(没有CPU Copy)
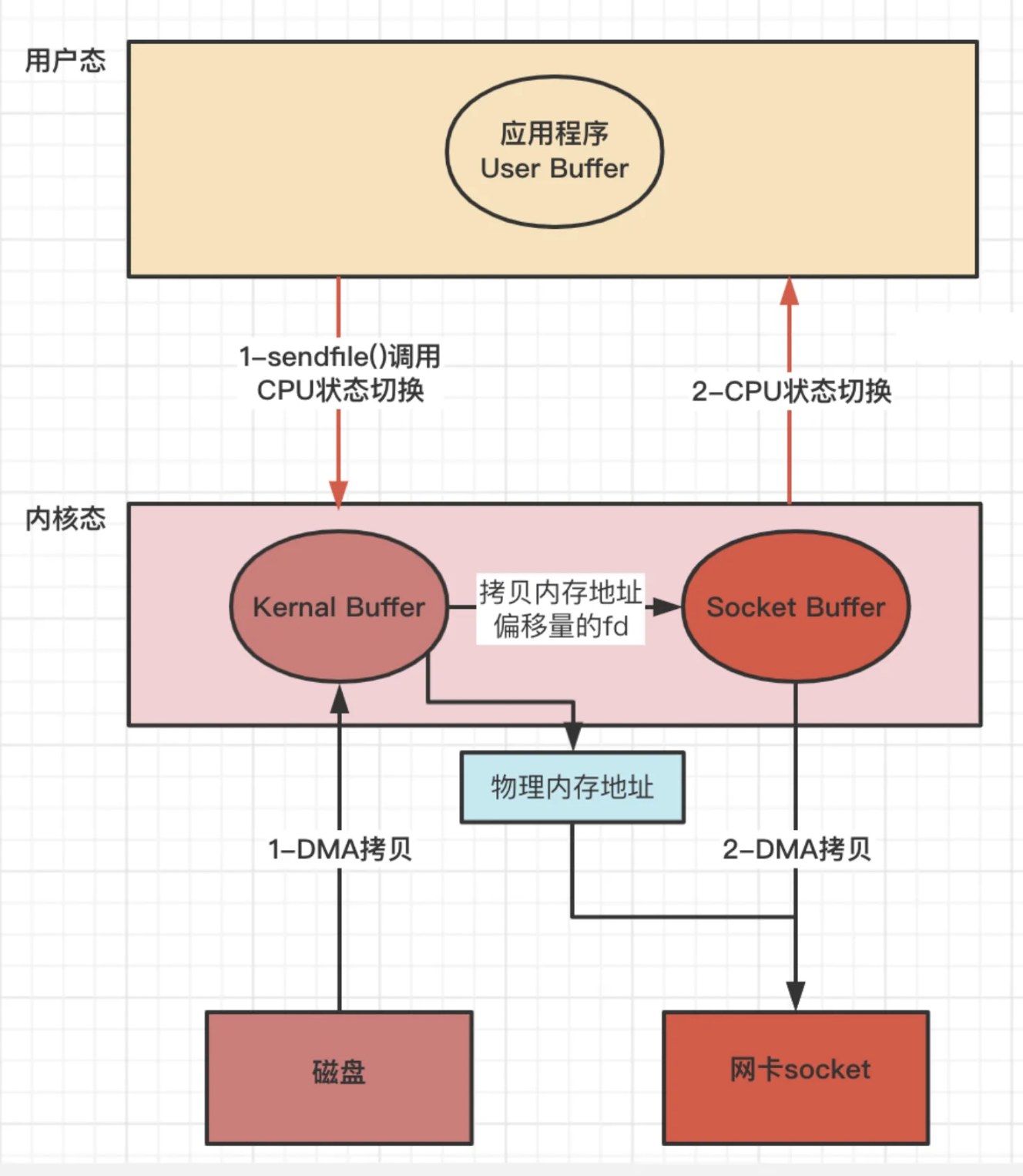
应用程序先调用sendfile()方法,将数据从磁盘拷⻉到内核缓冲区(DMA负责)
把内存地址、偏移量的缓冲区 fd 描述符 拷⻉ 到Socket Buffer中去 拷⻉很少的数据 可忽略
- 本质和虚拟内存的解决方法思路一样,就是内存地址的记录
然后把内核缓冲区的Socket Buffer给直接拷⻉给Socket协议栈 即网卡设备中,返回结束(DMA负责)
操作系统和计算机网络
计算机网络
OSI 七层模型、TCP/IP 四层模型和组成
网络通讯、TCP、UDP、HTTP1.0/1.1/2、HTTPS/网络安全攻防、DNS/CDN
性能优化诊断方法论
围绕两个大点
应用程序性能维度
提高吞吐量Throughput
降低延迟Latency
操作系统资源维度
CPU使用率
内存使用率
磁盘IO使用率
选择[指标]评估系统和应用程序现状
设置性能优化[目标]
进行链路基准[测试]
[分析]全链路性能瓶颈
[优化]系统和应用程序
[验证]优化后的性能指标
计算机硬件组成
1945年-科学家冯·诺依曼提了一种计算机设计实现架构,奠定现代计算机的理论基础
五大组成部分
中央处理器(Central Processing Unit,CPU)
控制器Control Unit 简称 [CU]
计算机的指挥系统,用来控制计算机其他组件的运行
运算器Arithmetic/Logic Unit 简称 [ALU]
(又名算数逻辑运算器)
运算功能,用来完成各种二进制编码做算术运算和逻辑运算,包括加减乘、与或非运算,控制器+运算器=CPU
运算器和控制器联系十分紧密,两大部件多数集成在同一芯片,统称为
存储器
内存
比如内存条 ,临时存储,断电丢失数据
外存
比如机械硬盘, 持久存储,断电不丢失数据
IO设备
输入设备input
比如键盘、鼠标、⻨克⻛、触摸屏、手写 输入板,游戏杆等
输出设备output
比如显示器、音响、打印机等
操作系统和进程
运行在计算机上最重要的一种程序,管理计算机的所有硬件和软件
用户通过系统OS来操作使用计算机硬件,属于中间层
现代操作系统核心功能
进程管理: 操作系统为进程分配任务,解决处理器的调度、分配和回收等
处理器管理: CPU的管理和分配,比如 分配进程 CPU调度执行
内存管理: 内存的管理和分配,比如给程序分配内存和释放内存
外存管理: 持久化存储的管理和分配,比如 磁盘文件写入
I/O管理: 输入/输出设备的管理,比如键盘输入和网络收发
进程
一个具有独立功能的程序对某个数据集在处理机上的执行过程,也是操作系统分配资源的基本单位
操作系统中给进程抽象了专⻔的[数据结构]
称为进程控制块,Process Control Block 简称 PCB
在操作系统代码当中是一个结构体: struct task_struct
每一个进程均有一个PCB,在创建进程时建立PCB,伴随进程运行的全过程,直到进程撤消而撤消
PCB数据结构 包含进程的多数信息
程序ID(PID、进程句柄): 一个进程都必须对应一个唯一PID,一般是整形数字
特征信息: 一般分系统进程、用户进程、或者内核进程等
进程状态: 运行、就绪、阻塞,表示进程现的运行情况
优先级: 表示获得CPU控制权的优先级大小
提供进程管理、调度所需要的信息
新建态: 进程正在被创建,操作系统为进程分配资源,初始化PCB
进程状态
就绪态: 具备运行条件,但没有空闲的CPU导致不能运行, 万事俱备,只欠一个CPU 运行态: 占有CPU,并在CPU上运行指令
阻塞态: 等待某一事件而暂时不能运行
退出态: 从系统中退出,操作系统会回收进程拥有的资源、撤销PCB
进程、线程、他们之间的关系是怎样的
进程
本质上是一个独立执行的程序,进程是操作系统进行资源分配和调度的基本概念
操作系统进行资源分配和调度的一个独立单位
线程
是操作系统能够进行运算调度的最小单位,它被包含在进程之中,是进程中的实际运作单位。
一个进程中可以并发多个线程,每条线程执行不同的任务,切换受系统控制。
重点
进程拥有多个线程的时候,这些线程会共享相同的虚拟内存和全局变量资源,这些资源在上下文切换时不需要修改
同进程内的线程切换,要比多进程间的切换消耗更少的资源,所以开发中用多线程代替多进程的原因
线程上下文切换的两种情况
- 前后两个线程属于不同进程,此时资源不共享,线程上下文切换和进程的上下文切换一样
- 前后两个线程属于同一个进程。同进程虚拟内存共享,在切换的时候虚拟内存等资源就保持不动,只需要切换线程的私有数据,寄存器等不共享的数据
进程创建
进程一般由OS内核创建,一个进程也可以去创建另一个进程,这个去创建进程称为父进程,被创 建进程称为子进程
应用场景
- Nginx 的master-worker进程
- Redis 两种持久化方式
- worker是处理真正的请求的,而master负责监控worker进程是否在正常工作
- AOF (append only file)和 RDB (Redis DataBase)
- 执行bgsave命令,Redis-Server会fork创建子进程,RDB持久化过程由子进程负责,会在后台异步进行快照操作,由于是子进程,所以快照生成同时还可以响应客户端请求
进程调度
Linux 是一个多任务操作系统,支持的任务同时运行的数量远远大于 CPU 的数量
进程调度 就是指【怎样安排】某一个时刻CPU运行【哪个进程】
进程调度类型
非抢占式调度 Nonpreemptive
一旦把处理机分配给某进程后,进程就会一直运行,直到该进程【完成】或【阻塞】时才会把 CPU 让给其他进程
主要用于【批处理系统】 和 某些对【实时性要求不严】的实时系统
抢占式调度 Preemptive
暂停某个正在执行的进程,将已分配给该进程的处理机重新分配给另一个进程
系统同样是把处理机分配给优先权最高的进程,在其执行期间出现了另一个其优先权更高的进程
进程调度程序就停止当前进程的执行,重新将处理机分配给新到的优先级最高的进程
主要用于比较严格的【实时系统】中
算法分类
先来先服务调度算法(FCFS,first come first served,非抢占式)
- 按照作业/进程到达的先后顺序进行调度 ,即: 优先考虑在系统中等待时间最⻓的作业
- 重点: 排在⻓进程后的短进程的等待时间⻓,不利于短作业/进程,⻓进程得到CPU就执行完成了,不利于短进程
- 比如 进程一响应慢,进程二/三/四响应快,那进程一先到,其他本来很快搞定的但是没被调度到导致效率慢
短作业优先调度算法(SJF, Shortest Job First,非抢占式)
- 预计执行时间短的进程优先分派处理机,短进程/作业(要求服务时间最短)
- 在实际情况中占有很大比例,为了使得它们优先执行,对⻓作业不友好
- 重点: 缩短进程的等待时间,提高系统的吞吐量
- 比如 进程一响应慢,进程二/三/四响应快,那同等时间下,更多短进程任务完成了,吞吐量也上去了
高响应比优先调度算法(HRRN,Highest Response Ratio Next,非抢占式)
- 在每次调度时,先计算各个作业的优先权: 优先权=响应比=(等待时间+要求服务时间)/要求服务时间
- 因为等待时间与服务时间之和就是系统对该作业的响应时间,所以 优先权=响应比=响应时间/要求服务时间
- 选择优先权高的进行服务需要【计算优先权信息,增加了系统的开销】是介于FCFS和SJF之间的一种折中算法
时间片轮转调度算法(RR,Round-Robin,抢占式)
- FCFS 的方式按时间片轮流使用CPU 的调度方式,让每个进程在一定时间间隔内都可以得到响应
- 由于高频率的进程切换,会增加了开销,且不区分任务的紧急程度
优先级调度算法(Priority Scheduling ,有抢占式和非抢占式)
- 根据任务的紧急程度进行调度,高优先级的先处理,低优先级的慢处理
- 通常使用【动态优先级】,如果高优先级任务很多且持续产生,那低优先级的就可能很慢才被处理
- 分类
- 优先级因素: 进程的等待时间、已使用的处理机时间或其他资源的使用情况
- 非抢占式
- 当就绪队列中出现优先级高的进程,运行完当前进程,再选择优先级高的进程。
- 抢占式
- 当就绪队列中出现优先级高的进程,当前进程挂起,调度优先级高的进程运行。
多级反馈队列调度算法(Multilevel Feedback Queue,抢占式)
- 多级: 表示有多个队列,每个队列优先级从高到低,同时优先级越高时间片越短
- 高优先级队列中已没有调度的进程,则调度次优先级队列中的进程
- 对同个队列中的各个进程,按照时间片轮转法调度
- 比如
- Q1,Q2,Q3三个队列,在Q1中没有进程等待时才去调度Q2,只有Q1,Q2都为空时才会去调度 Q3
- 队列的时间片为N,假如Q1中的作业经过N个时间片后还没有完成,则进入到Q2队列,以此类推
- 反馈: 表示如果有新的进程加入优先级高的队列时,立刻停止当前正在运行的进程,转而去运行优先级高的队列
算法总结
一个好的调度算法考虑以下几个方面
- 公平-保证每个进程得到合理的CPU时间
- 高效-使CPU保持忙碌状态,总是有进程在CPU上运行
- 响应时间-使交互用户的响应时间尽可能短
- 周转时间: 使批处理用户等待输出的时间尽可能短
- 吞吐量-使单位时间内处理的进程数量尽可能多
不同系统和版本支持的调度算法不一样
- UNIX采用动态优先队列调度
- BSD采用多级反馈队列调度
- Windows采用抢先多任务调度
磁盘分区
计算机中存放信息的主要的存储设备就是硬盘,但是硬盘不能直接使用,必须对硬盘进行分割一块一块的硬盘区域就是磁盘分区
为啥要磁盘分区?
(可以想下 mysql数据库 为啥要分库分表)
方便管理、提升系统的效率和做好存储空间隔离分配
将系统中的程序数据按不同的使用分为几类,将不同类型的数据分别存放在不同的磁盘分区中
在每个分区上存放的都是相似的数据或程序,这样管理和维护就容易多
分区可以提升系统的效率,系统读写磁盘时,磁头移动的距离缩短了,即搜寻的范围小了
如果不运用分区,每次在硬盘上寻找信息时可能要寻找整个硬盘,所以速度会很慢
允许在一个磁盘上有多个文件系统,每个分区可以分配不同的文件系统
从而使操作系统可以识别每个分区的文件系统,从而实现文件的存储和管理
创建硬盘分区后,还不能立即使用,还需要创建文件系统,即格式化
格式化后常⻅的磁盘格式有: FAT(FAT16)、FAT32、NTFS、ext2、ext3等
硬盘分区类型
(不同类型磁盘支持分区的数量有限制)
主分区
主直接在硬盘上划分的,一个硬盘可以有1到3个主分区和1个扩展分区
拓展分区
是一个概念实际在硬盘中是看不到的,也无法直接使用扩展分区,在扩展分区中建立逻辑分区
容量
硬盘的容量=主分区的容量+扩展分区的容量
扩展分区的容量=各个逻辑分区的容量之和
零拷贝
下图应用程序从磁盘读取数据发送到网络上的损耗,程序需要两个命令 先read读取,再write写出
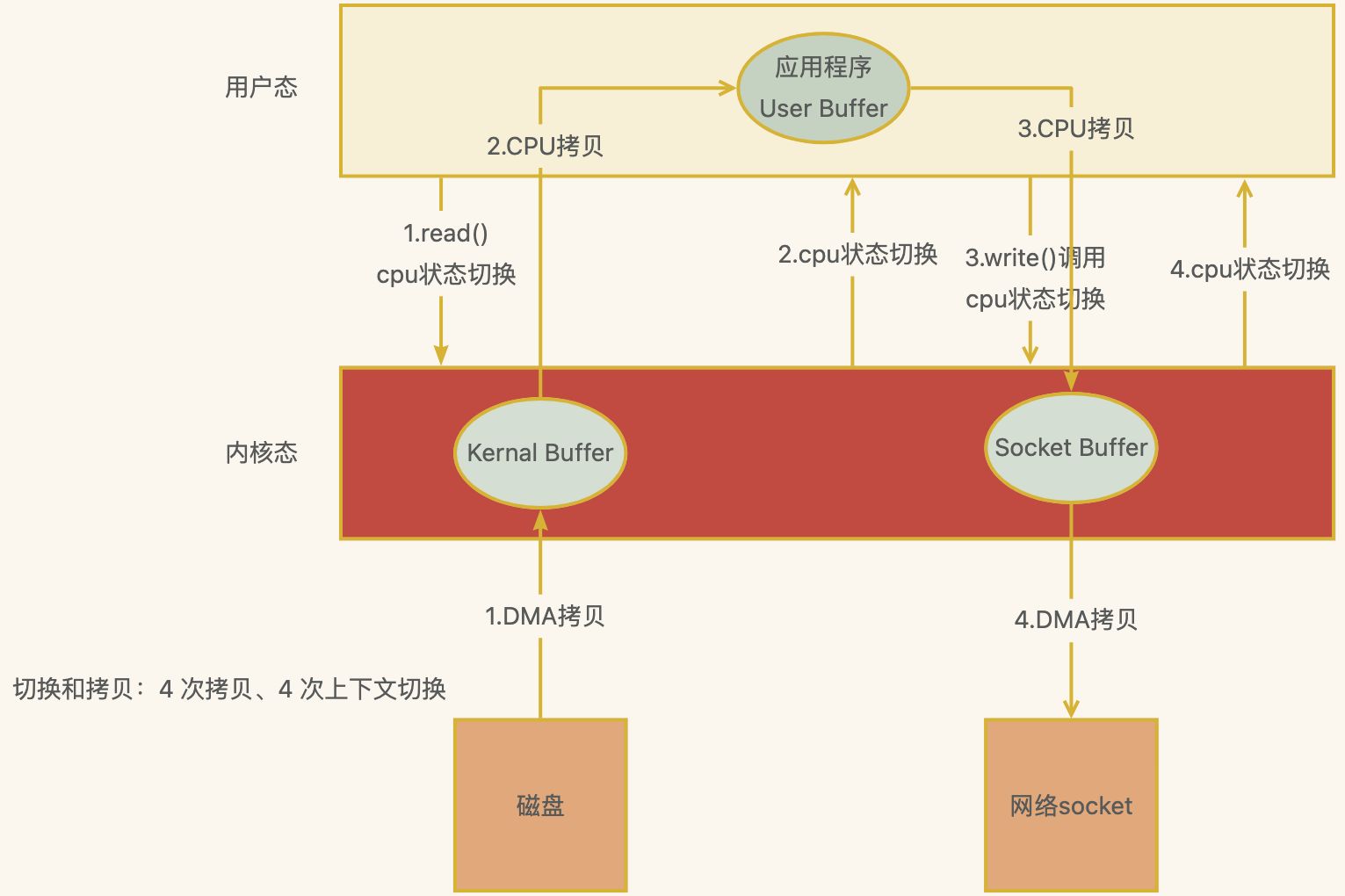
切换和拷贝:4 次拷贝、4 次上下文切换
mmap 函数
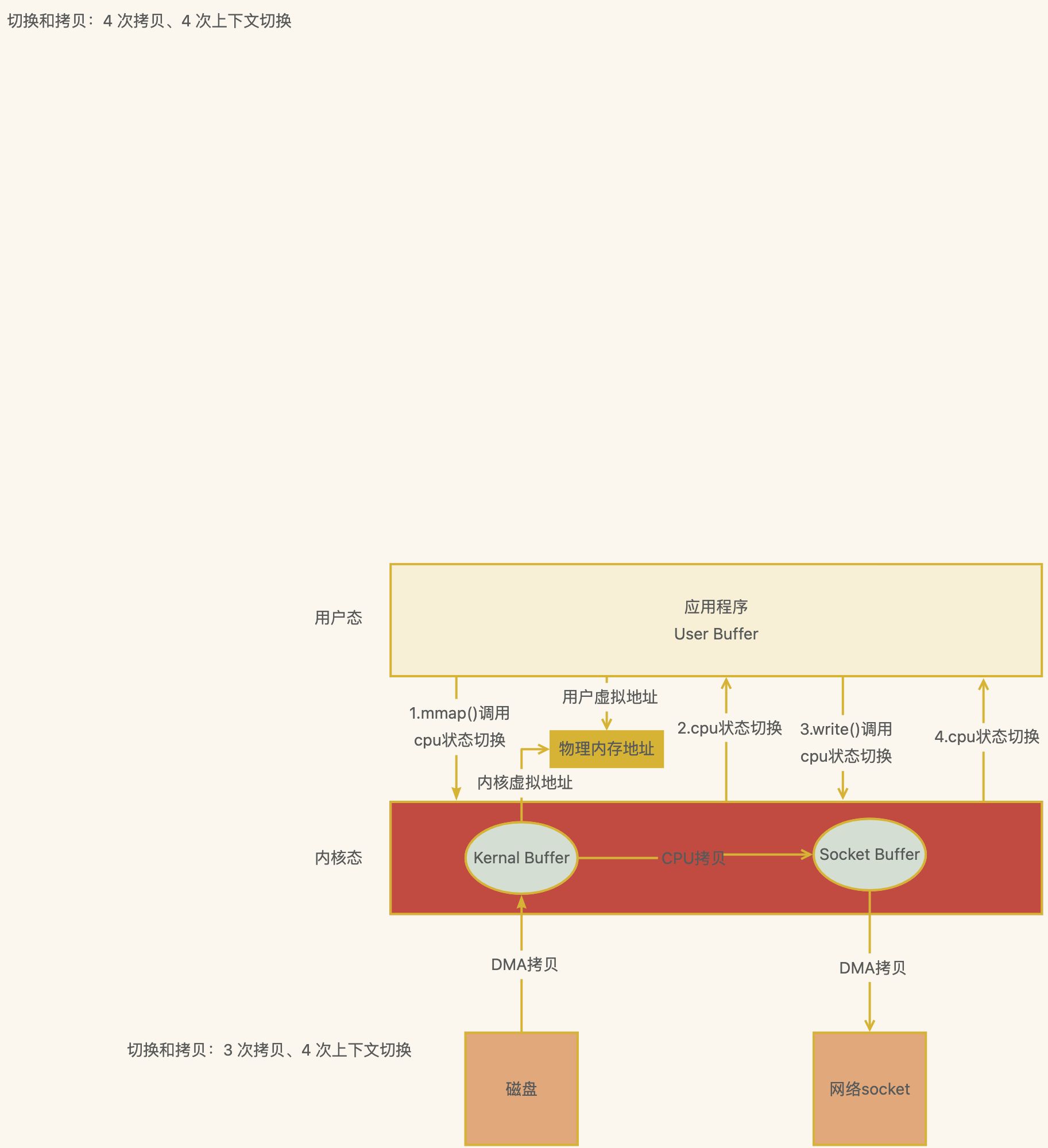
切换和拷贝:3 次拷贝、4 次上下文切换
sendfile 函数 优化前
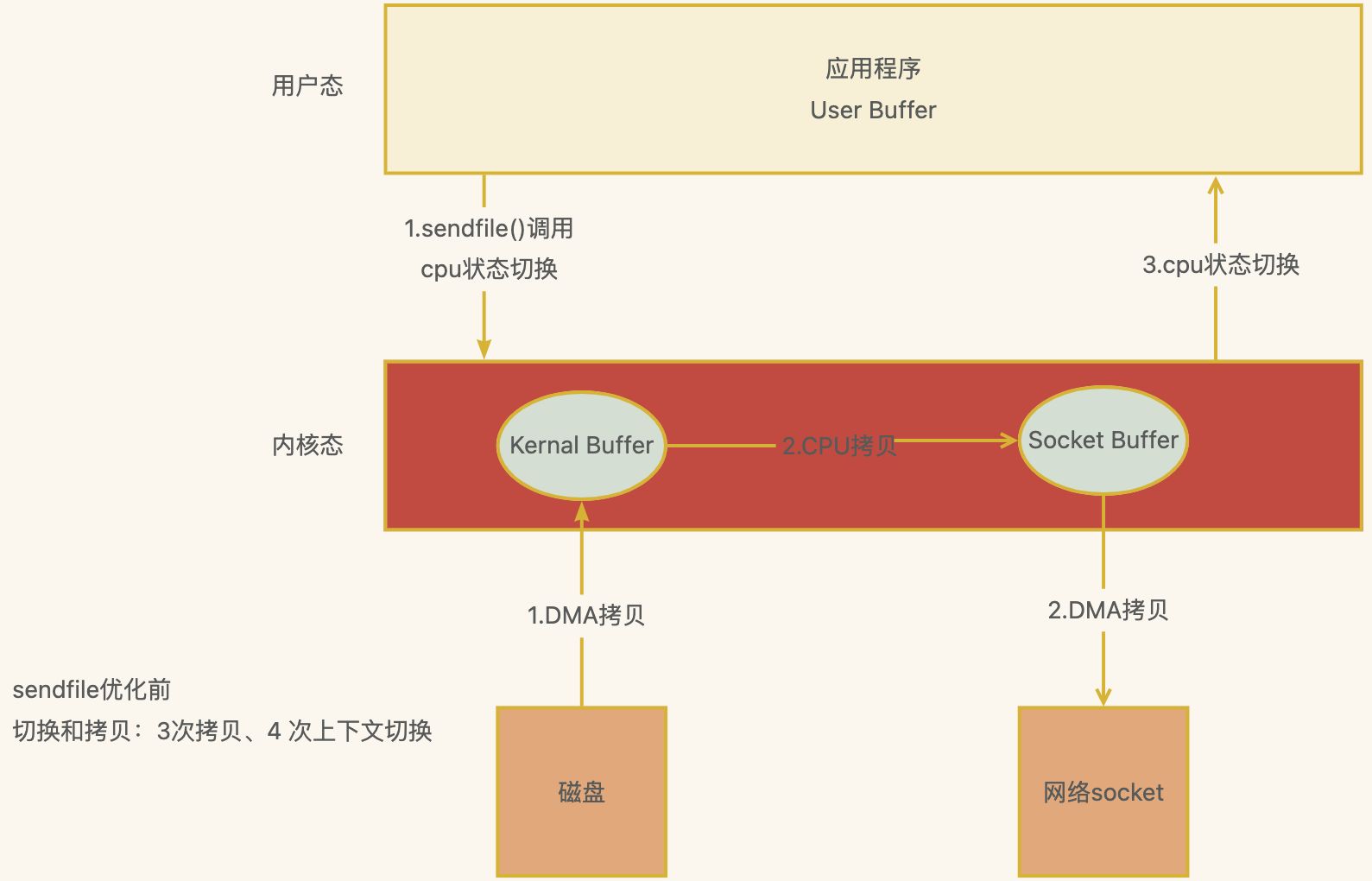
切换和拷贝:3 次拷贝、2 次上下文切换
结合上述方法优化后的 sendfile 零拷贝,结合 mmap+sendfile,CPU 拷贝的时候借鉴 mmap 的思想
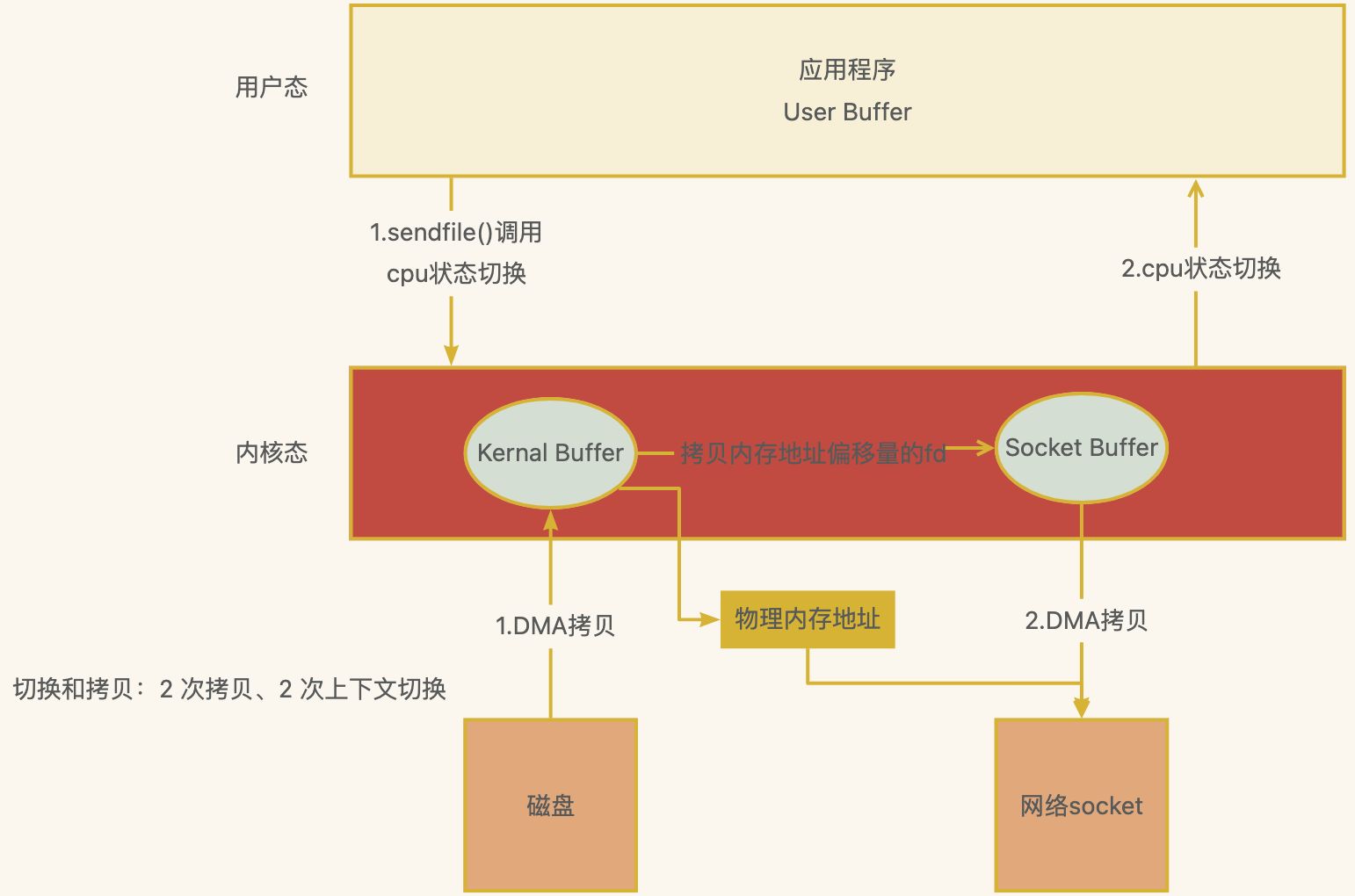
切换和拷贝:2 次拷贝、2 次上下文切换
零拷⻉技术和优缺点总结
零拷⻉的目标
解放CPU,避免CPU做太多事情
减少内存带宽占用
减少用户态和内核态上下文切换过多
在文件较小的时候 mmap 耗时更短,当文件较大时 sendfile 的方式最优
零拷⻉方式对比
sendfile
无法在调用过程中修改数据,只适用于应用程序不需要对所访问数据进行处理修改情况
场景
比如 静态文件传输,MQ的Broker发送消息给消费者
如果想要在传输过程中修改数据,可以使用mmap系统调用。
文件大小:适合大文件传输
切换和拷⻉: 2次上下文切换,最少 2 次数据拷⻉
mmap
在mmap调用可以在应用程序中直接修改Page Cache中的数据,使用的是mmap+write两步
调用比sendfile成本高,但优于传统I/O的拷⻉实现方式,虽然比 sendfile 多了上下文切换
但用户空间与内核空间并不需要数据拷⻉,在正确使用情况下并不比 sendfile 效率差
场景
多个线程以只读的方式同时访问一个文件, mmap 机制下多线程共享同一物理内存空间,节约内存
文件大小:适合小数据量读写
切换和拷⻉: 4 次上下文切换,3 次数据拷⻉
计算机网络

套娃一样的封装数据包,比如TCP协议是封装在IP数据包中

OSI 七层模型和TCP/IP 四层模型 两个模型哪个更好?
两个模型各有各的好,前者更详细,后者容易理解
例子
TCP/IP 四层模型 网络加密传输
HTTPS 在 HTTP 与 TCP 层之间加入了 SSL/TLS 协议
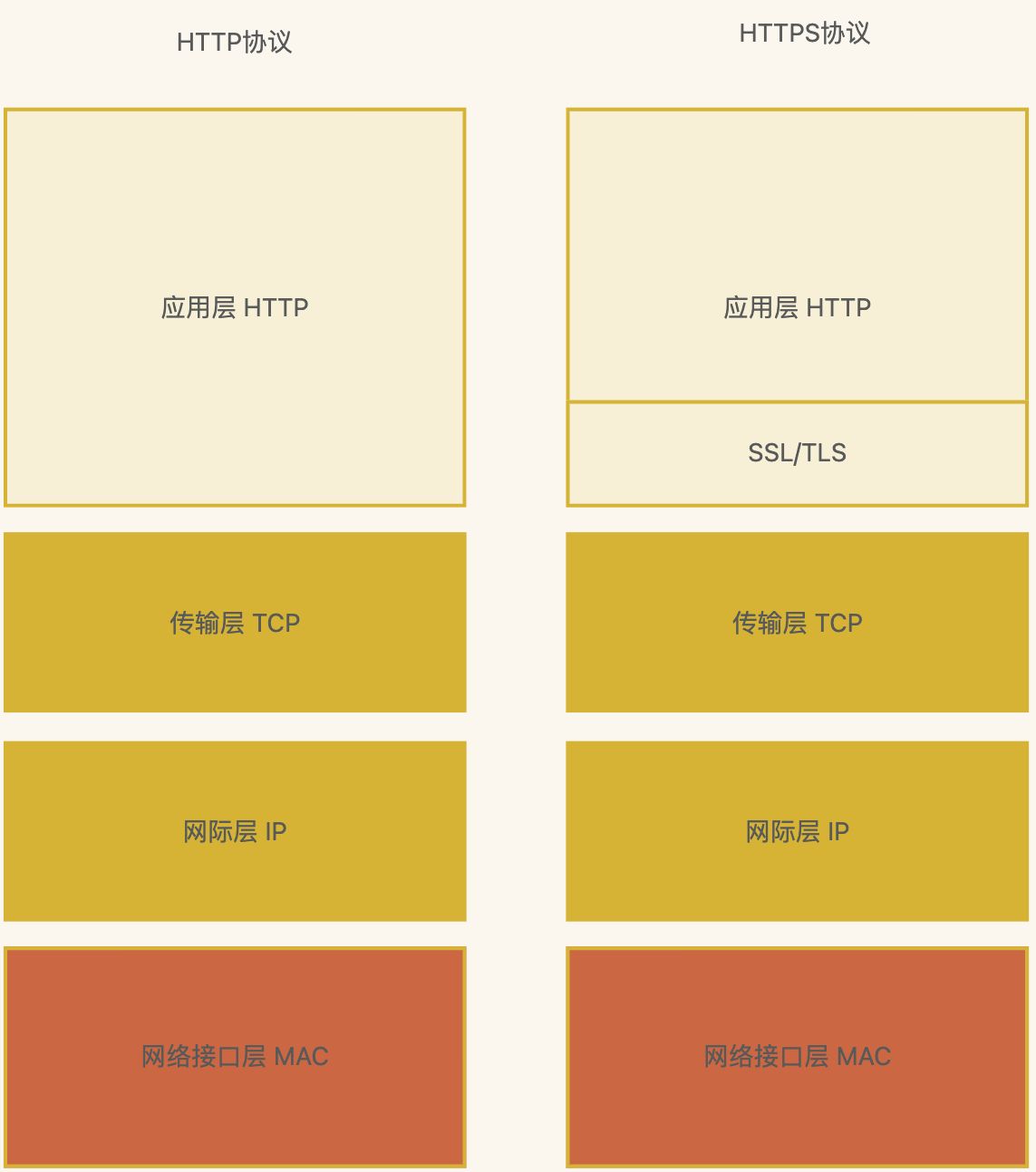
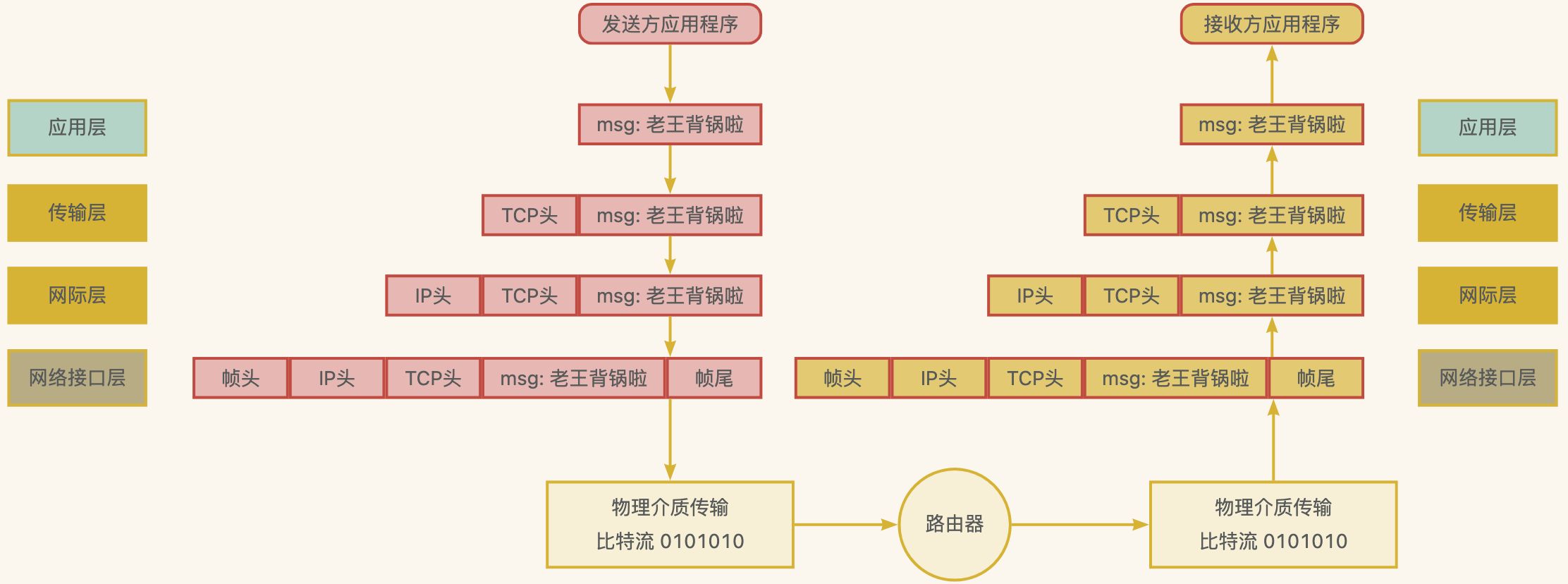
网络分层模型和主要协议

网络分层模型下,数据在各层之间的传输
类似寄快递,中转站一层层分发,省->市->县->区->村->房号->具体联系人
发送数据包
在网络协议栈中从上到下逐层处理,最终送到网卡发送出去
接收数据包
需要经过网络协议栈从下到上的逐层处理,最后送到应用程序中使用
注意
应用层是直接面向用户的一层,为应用程序提供统一协议的接口,但不是应用程序
目的是保障不同类型的应用采用的低层通信协议是一致的
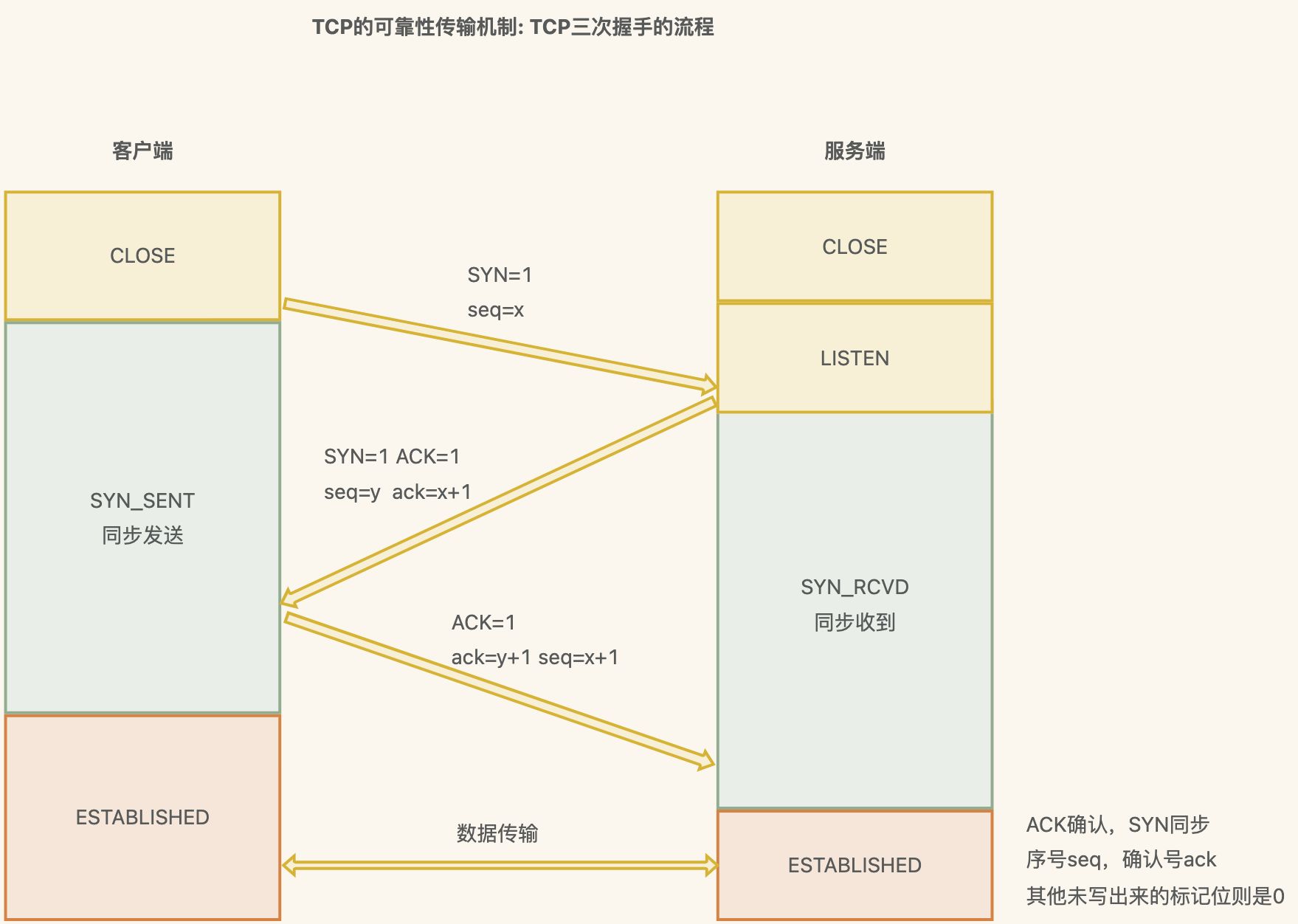
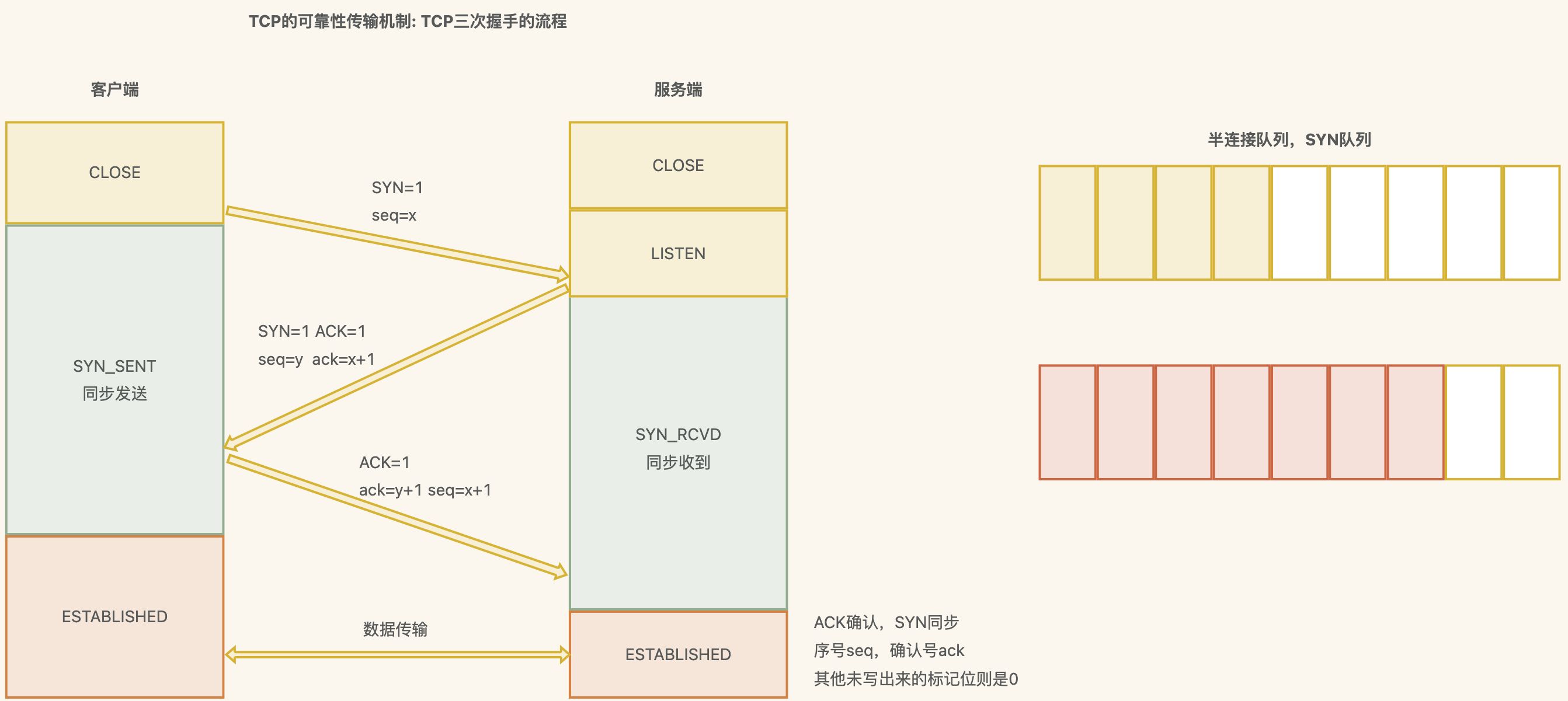
TCP 三次握手详细流程
一次握手: 客户端发送一个SYN(Synchronize)数据包到服务器,用来请求建立连接,状态变为 SYN_SEND;
报文首部中的同部位SYN=1,同时随机生成初始序列号 seq=x
二次握手: 服务器收到客户端的SYN数据包,并回复一个SYN+ACK 数据包,用来确认连接,状态变为SYN_RECEIVED;
确认报文中应该 ACK=1,SYN=1,确认号是ack=x+1,同时随机初始化一个序列号 seq=y
三次握手: 客户端收到服务器的SYN+ACK数据包,并回复一个ACK 数据包,用来确认连接建立完成,状 态变为ESTABLISHED
确认报文的ACK=1,ack=y+1,seq=x+1
出于安全的考虑 第1次握手不能携带数据,第3次握手是可以携带数据的。

TCP为什么要三次握手而不是二次或者四次
案例一:两端同步确认序列号
案例二:防止失效的连接请求报文段被服务端接收
结论
三次握手的主要目的是保证连接是 双工+可用 的,保证双方都具有接受和发送数据的能力
防止重复历史连接的初始化 ,避免资源的浪费
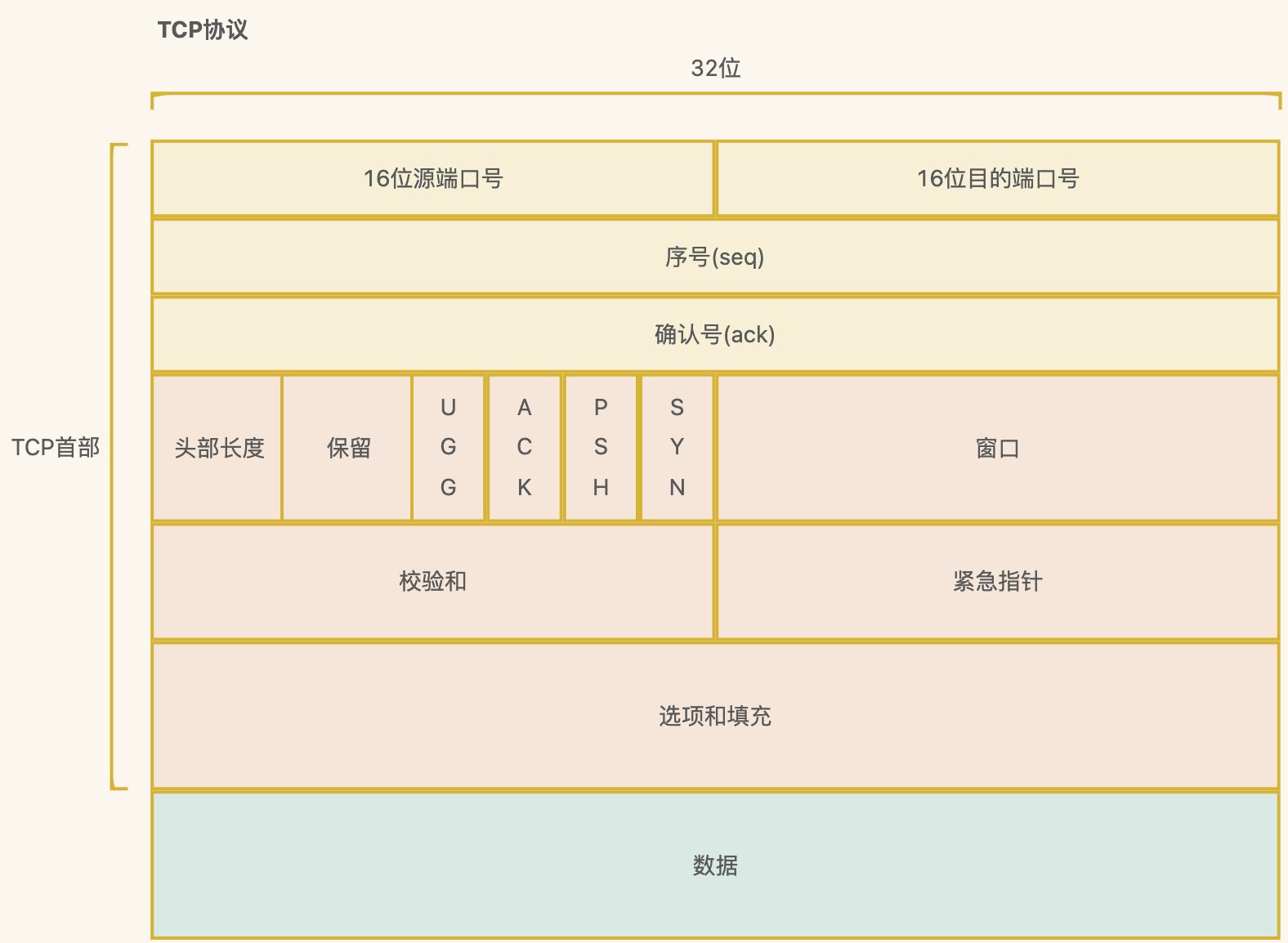
同步双方初始序列号
序列号seq: 用来解决网络包乱序问题
确认号ack: 用来解决丢包的问题
记住: 可靠性传输主要是通过重传机制来保证
TCP 洪水攻击
TCP洪水攻击 基础缓解方案:TCP SYN Cookies (延缓TCB分配)
使用连接信息(源地址、源端口、目的地址、目的端口等)和一个随机数,计算出一个哈希值(SHA1)
SYN-Cookie避免内存空间被耗尽,但是加密会消耗CPU
攻击者发送大量的ACK包过来,被攻击机器将会花费大的CPU时间在计算Cookie上,造成正常的逻辑无法被执行
哈希值 被用作序列号 应答 SYN+ACK 包,客户端发送完三次握手的最后一次 ACK ,
服务器就会重新计算这个哈希值,确认是之前的 SYN+ACK 的返回包,则进入 TCP 的连接状态。
当开启了 syncookies 功能就可以在不使用 SYN 半连接队列的情况下成功建立连接,不需要维护半连接 数的限制
如果是DDOS则难解决,需要花钱购买流量设备
shell
# 开启syncookies 阿里云ECS默认开启
# vim /etc/sysctl.conf
net.ipv4.tcp_syncookies = 1
0 值,表示关闭该功能;
1 值,表示仅当 SYN 半连接队列放不下时,再启用它;
2 值,表示无条件开启功能其他解决方案
增大半连接队列和全连接队列;
减少 SYN+ACK 重传次数(减小tcp_synack_retries的值)
收到syn攻击时,服务端会重传syn+ack报文到最大次数,才会断开连接,所以可以减少重传次数
遇到服务器运行异常,现象和思路总结
当发现服务器或业务卡顿的时候,通过top命令来查看服务器负载和cpu使用率,然后排查cpu占用较高 的进程
如果发现cpu使用率并不高,但是si软中断很高,且ksoftirqd进程cpu占用率高,则说明服务器持续发生 软中断
通过cat /proc/softirqs 来分析是哪类型的软中断次数最多,watch命令来查看变化最快的值(watch -d cat /proc/softirqs)
多数情况下网络发生中断的情况会比较多,通过sar命令来查看收发包速率和收发包数据量(sar -n DEV 1 -h)
验证是否是网络收发包过多导致,计算每个包的大小,判断服务器是否收到了flood攻击
通过tcpdump来抓包,分析数据包来源ip和抓包数据中的Flags来分析数据包类型 (tcpdump -i eth0 -n tcp port 80)
如果是Flood洪水攻击,可以通过调整tcp链接参数策略和防火墙封禁异常ip
如果是大规模DDOS攻击,则花钱找运营商购买流量包封堵
TCP 四次挥手详细流程
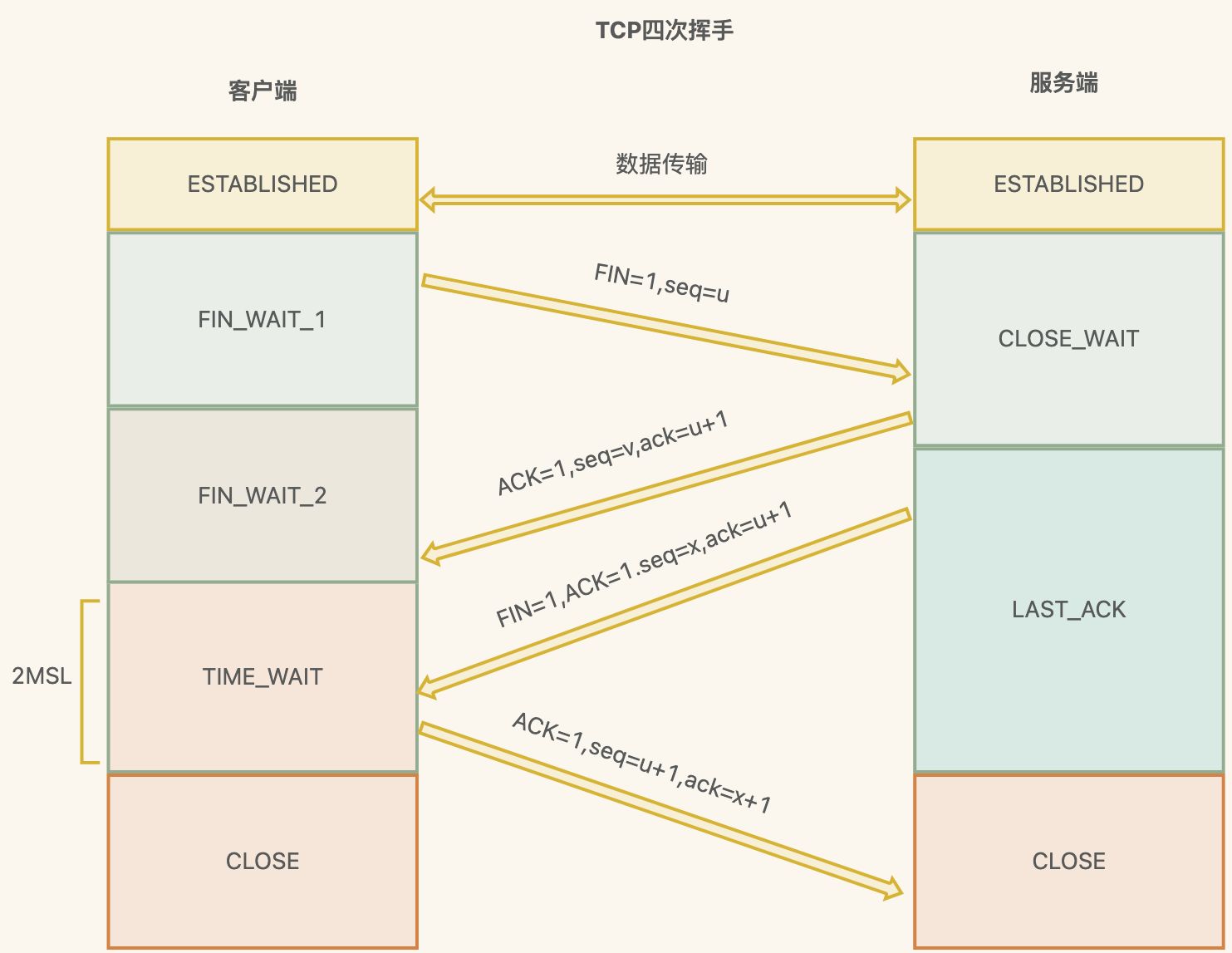
第一次
客户端发送 FIN(Finish)报文段,用于关闭客户端到服务端的数据传输,表示客户端的数据发送 完毕;
客户端进入 FIN_WAIT_1 状态
第二次
服务端收到客户端的FIN报文段后,发送ACK报文段,确认收到了客户端的FIN报文段
服务端进入CLOSE_WAIT状态,客户端接收到这个确认包后进入 FIN_WAIT_2 状态
第三次
服务端发送FIN报文段,用于关闭服务端到客户端的数据传输,表示服务端的数据发送完毕
服务器端进入 LAST_ACK 状态,等待客户端的最后一个 ACK
第四次
客户端收到服务端的FIN报文段后,发送ACK报文段,确认收到了服务端的FIN报文段
客户端接收后进入TIME_WAIT状态,在此阶段下等待2MSL时间(两个最大段生命周期,2Maximum Segment Lifetime)
如果这个时间间隔内没有收到服务端的请求,进入CLOSED状态;服务器端接收到ACK确认包之后,也进入 CLOSED 状态。
从而完成TCP四次挥手
TCP 四次挥手疑问点
Q: 为啥要等待2MSL时间?
2MSL是报文最大生存时间,是任何报文在网络上存在的最⻓时间,超过这个时间报文将被丢弃
假如最后一次客户端发送ACK给服务端没收到,超时后 服务端 重发FIN,客户端响应ACK,来回就是2个 MSL
等待2MSL,可以让本次连接持续的时间内所产生的所有报文段都从网络中消失,避免旧的报文段
RFC 793中规定一个MSL为2分钟,实际应用中常用的是30秒,1分钟和2分钟
CLOSE-WAIT 和 TIME-WAIT 的区别
CLOSE-WAIT是等待关闭
服务端收到客户端关闭连接的请求并确认之后,进入CLOSE-WAIT状态。
但服务端可能还有一些数据没有传输完成,不能立即关闭连接
所以CLOSE-WAIT状态是为了保证服务端在关闭连接之前将待发送的数据处理完
TIME-WAIT是在第四次挥手
当客户端向服务端发送ACK确认报文后进入TIME-WAIT状态,主动关闭连接的,才有time_wait状态
在HTTP请求中,如果connection头部的取值设置为close,那么多数都由服务端主动关闭连接
服务端处理完请求后主动关闭连接,所以服务端出现大time_wait状态
防止旧连接的数据包
如果客户端收到服务端的FIN报文之后立即关闭连接,但服务端对应的端口并没有关闭
客户端在相同端口建立新的连接,可能导致新连接收到旧连接的数据包,从而产生问题
保证连接正确关闭
假如客户端最后一次发送的ACK包在传输的时候丢失,由于TCP协议的超时重传机制,服务端 将重发FIN报文
如果客户端不是TIME-WAIT状态而直接关闭的话,当收到服务端重送的FIN包时,客户端会用 RST包来响应服务端
导致服务端以为有错误发生,但实际是关闭连接是没问题的
TIME-WAIT状态有啥坏处?
占用文件描述符/内存资源/CPU 和端口